
CLIP:多模态奠基性代表作 | 用自然语言来做视觉模型
引言
在之前的文章中我们详细地介绍了自监督学习中的一类分支,即对比学习。简单来说,它通过在特征空间中拉近同一实例的不同视图间的距离,同时推远不同实例之间的距离促使模型学习到每个实例自己的 Representation。很多工作也证明了这种方法在面对无标注数据时的优势,并且可以通过简单的微调就能适应各种复杂的下游任务。
其实现在回看也很自然,自监督学习为我们提供了“预训练-微调”的AI范式,其中大范围的预训练就可以有效让模型理解数据,从而就能实现 Few-Shot 甚至 Zero-Shot(少样本/零样本学习)。而如果把对比学习中的“同一实例”看得更泛化一点,它不一定非得指不同视角下拍摄到猫的图片,它甚至可以是多模态的,也就是一句描述猫的文本和一张猫的图像,这二者也可以是“同一个实例”的不同“视角”。换句话说把这里提到了的文本和图像当成一对正样本,其实没有问题。
这种朴素的设想最终被 OpenAI 在 2021 年发布于 ICML 上的论文 Learning Transferable Visual Models From Natural Language Supervision 被证实确实是有用的,并且一举成为了多模态学习领域的奠基之作。它就是 CLIP,即 Contrastive Language-Image Pre-training,对比语言-图像预训练。
CLIP 将4 亿个图像和文本对 (image-text pairs)以自监督的方式进行训练,将文本和图像映射到同一个嵌入空间(embedding space)中。正如刚才的举例一样,,一只猫的图片和一个关于猫的句子“一只猫的图片” 之间将具有非常相似的嵌入,并在向量空间中彼此接近。这一点非常重要,因为你可以用这样的模型构建许多有趣的应用,例如可以实现用文本描述来对图像数据库进行检索,反之亦然。
CLIP 的作者同样发现 CLIP可以用于各种未经过训练的任务。例如,它在多个基准测试上取得了显著的 零样本 性能。例如在 ImageNet 图像分类数据集上,CLIP 并没有在 ImageNet 数据集内的任何 128 万个训练样本上进行训练但是他的准确度与基于 ImageNet 训练的 ResNet-50 相媲美。
模型框架
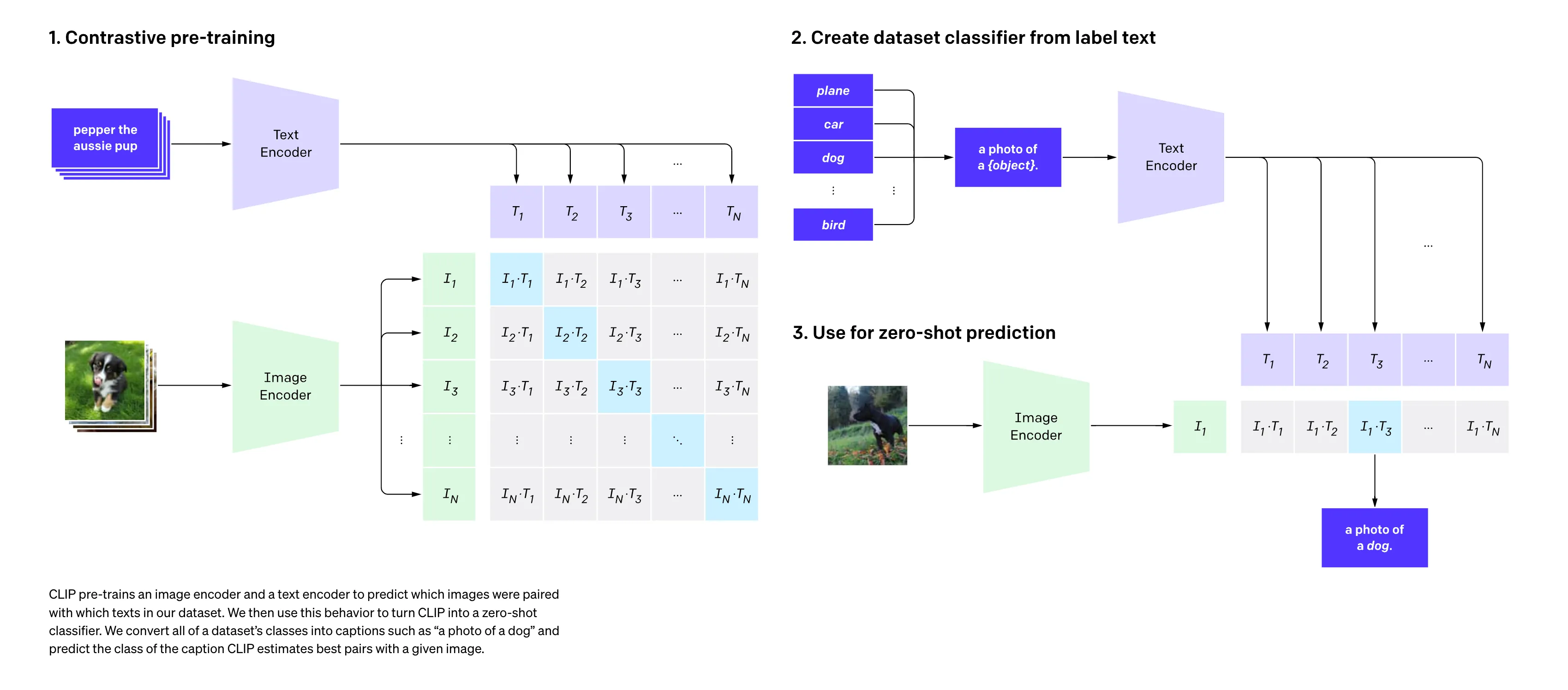
对比预训练
CLIP 在对比学习设计上其实并没有做更多创新,沿用了 SimCLR 那样 end-to-end 的对比学习框架,也就是负样本仅来源于一个 内部,没有引入外部存储器把更多负样本纳入计算。具体来说,在一个 内,假设 batch_size=N,那么:
- 模型的输入: 个 image-text pairs.
- 第 个 image embedding 对应的正样本就是第 个 text embedding,其余的 个 text embedding 都是负样本,对应上图矩阵中的每一行;
- 第 个 text embedding对应的正样本就是第 个 image embedding,其余的 个 image embedding 都是负样本,对应上图矩阵中的每一列;
- CLIP 因此分别将 image embedding 和 text embedding 都视为 锚点(anchor),从而采用了双向对比损失:
在具体代码实现上, 采用余弦相似度, 内相当于做了 操作后再取出对应索引的那一项。通常经过 激活函数之前的每一项通常称为。此外,上述公式可以利用 nn.CrossEntropyLoss 简化书写,最终给出了伪码如下:

⚠️注意:因为 CLIP 模型过于庞大,并且在大量的数据集上进行训练,训练成本过高,所以不太好做调参的工作。因此作者在计算对比学习的目标函数时,将 temperature: 设置为可学习的 log-parametized(保证大于0) 乘法标量.
推理阶段
CLIP 经过预训练后只能得到视觉上和文本上的表征,实际上并没有在任何分类的任务上去做继续的训练或微调,所以它没有分类头,那么 CLIP 是如何做推理的呢?
首先,作者直接将 ImageNet 的分类标签(原英文单词而不是机器学习中常使用的索引)比如cat, dog, bird 加上前缀提示词(Prompt) 模板 A photo of a ...,最终组成一个句子,如 A photo of a dog。ImageNet 数据集中有1000个类,因此这里也可以一共得到 1000 个句子。
接下来,就用我们需要推理/分类的图像经过 Encoder 得到 image embedding 之后,与这1000个句子经过 Encoder 得到的 text embedding 进行相似度匹配,找出得分最高的那个句子(也就变相找到了对应的单词和分类标签),相当于间接把这个图像进行了分类。
这个操作就相当于使用了自然语言进行了监督(Natural Language Supervision)训练出来的视觉模型一样,也就对应了 CLIP 原始这篇论文的标题。
值得一提的是,CLIP 的编码器均是随机初始化从头训练的,训练阶段均没有用到 ImageNet 的任何内容(之后也没有用它来微调),但是对它做推理的效果却能比肩 ResNet。不仅如此,这个类别的标签也是可以改的,不必非得是 ImageNet 中的1000个类,可以换成任何的单词;这个图片也不需要是 ImageNet 的图片,也可以是任何的图片,依旧可以通过算相似度来判断这图中含有哪些物体。即使这个类别标签是没有经过训练的,只要图片中有某个物体也是有很大概率判断出来的,这就实现了Zero-Shot 零样本迁移!
下面这个实验也给出了 CLIP 相比于 ResNet 在迁移到不同数据集时的杰出表现: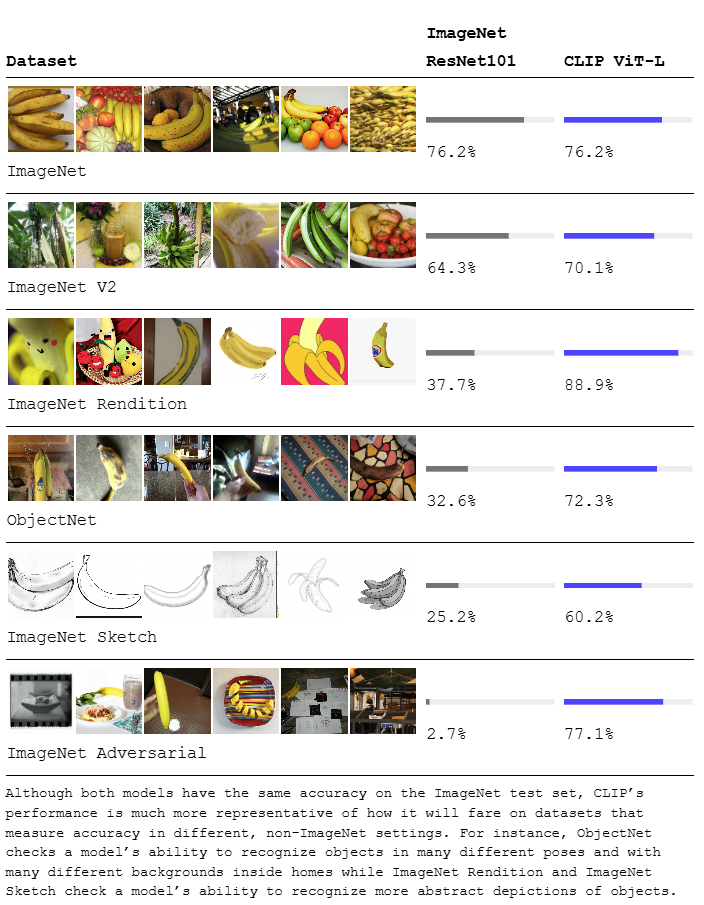
尽管 Resnet101 在 ImageNet 上的准确度很高,但如果迁移到其他数据集上,它对于香蕉的识别准确度就大幅下降。但反观 CLIP,它可以识别动漫里的、表情包里的、素描画里的各种类型的香蕉,迁移能力很强。
数据集
作者提到,现有的图像数据集都太小了。像 ImageNet 21k 才有 1400 万张图片。还有一些数据集虽然够大,但是标注质量很差。另外,虽然有谷歌的 JFT300 数据集(3亿个样本),但那是人家内部的,没有公开。所以 OpenAI 决定自己造一个超大号数据集。他们收集了 4亿个图片-文本对,构建了 WebImageText (WIT) 数据集。
模型局限性
作者在第六章介绍了 CLIP 的局限性。
首先,虽然 CLIP 在 Imagenet 上与 ResNet 50 打成平手。但后者远远不是 State-Of-The-Art Model。CLIP 离表现最好的模型还差了十几点精度。尽管大规模训练能够极大地促进模型精度,但作者预估,要媲美现今表现最好的模型,计算量至少要扩大 1000 倍。即使对于 OpenAI 来说,以现有的硬件也无法承担这个计算量。
另一个问题在于,如果做推理的数据真的和训练数据差得非常远 (out of distribution),那么 CLIP 的泛化效果会很差。作者举了个例子,在 MNIST 数据集上(1-9手写数字图片),CLIP 只达到了88%的准确度,还不如一个作用在像素点上的逻辑回归。虽然 4 亿数据集很大,但是很有可能没有包含这种不常见的手写数字的图片。这就引起了一些疑虑:CLIP 的强大有多大程度上取决于这个高质量、大规模的数据集。
还有一点,CLIP 在推理阶段,需要我们手动地设置“多项选择题”。作者设想,如果能够让网络自动生成文本来描述图片就好了。另外作者还提到了数据利用效率不高的问题。最后,一个没有办法回避的问题——数据本身的偏见带来的模型的偏见。这个在 GPT-3 里就有所体现。对此我的看法是,如果人类社会中还有这种偏见,我们如何寄希望于人工智能,希望它能克服这种偏见呢?
更多实验细节
BLIP
open_clip 库
open_clip 是一个由 LAION 团队推出,完全开源实现 的 CLIP 模型库,旨在复现并扩展 OpenAI 的 CLIP(Contrastive Language–Image Pre-training)模型功能。
它支持多种模型架构(如 ResNet、Vision Transformer)和文本编码器(如 BERT、Transformer),并提供丰富的预训练权重(基于 LAION 等数据集训练),适用于多模态任务(图像-文本匹配、zero-shot识别等)。
1 | # 安装 |
核心功能
- 提供多种预训练模型:
1 | >>> import open_clip |
支持 Hugging Face 模型加载:
1
2
3
4
5
6
7import torch
from PIL import Image
import open_clip
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')
model.eval() # model in train mode by default, impacts some models with BatchNorm or stochastic depth active
tokenizer = open_clip.get_tokenizer('ViT-B-32')将图像和文本映射到同一语义空间:
1
2
3
4
5
6
7
8
9
10
11
12image = preprocess(Image.open("example.png")).unsqueeze(0)
text = tokenizer(["a photo of a cat", "a photo of a dog"])
with torch.no_grad(), torch.autocast("cuda"):
image_features = model.encode_image(image) # Size: (B=1, D)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1) # Size: (B, B)
print("Label probs:", text_probs)
进阶功能
使用
--use-bf16或--precision amp启用自动混合精度训练:1
python -m open_clip.train --use-bf16 ...
多GPU训练:
1
torchrun --nproc_per_node=4 open_clip/train.py ...
部署到推理引擎(如 ONNX Runtime):
1
2
3
4import torch
dummy_image = torch.randn(1, 3, 224, 224)
dummy_text = torch.randint(0, 10000, (1, 77))
torch.onnx.export(model, (dummy_image, dummy_text), "clip_model.onnx")


