KV Cache
MHA 即 Multi-Head Attention,多头注意力机制,是 Transformer 的核心机制,我们想必对其已经谈不上陌生了。在其线性化之路中,我们关注的是它的时空复杂度的优化,主要是希望在训练和推理阶段,其计算复杂度能从原来的二次复杂性降低到线性的O(n) 级。而 MHA 在 LLM 中的应用已经充分印证了其强大的能力,LLM 得以成功也与 Scaling Law (参数量越大性能越好)密不可分。也因此,在训练一个大语言模型时,我们并不会对训练过程中的时空复杂度有着过大的需求;但反过来,在推理过程中,我们希望相同长度的上下文能尽可能地在更小的缓存空间内进行,以实现更快的推理速度或者更大的吞吐总量。要实现这一点,我们就需要对 MHA 中的 KV Cache 进行优化。
能一张卡部署的,就不要跨多张卡;能一台机部署的,就不要跨多台机。这是因为“卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”,由于“木桶效应”,模型部署时跨的设备越多,受设备间通信带宽的的“拖累”就越大。
现如今的 LLM 都是 Decoder-only 的,所以实际上上采用的 MHA 是 Masked 的,换句话说是一种 Causal Attention。它使得第t+1 个 token 的输出只依赖前t 个token,而与未来的 token 无关。写成公式就是下面这样:
ot=[ot(1),ot(2),⋯,ot(h)]ot(s)=Attention(qt(s),k≤t(s),v≤t(s))≜∑i≤texp(qt(s)ki(s)⊤)∑i≤texp(qt(s)ki(s)⊤)vi(s)qi(s)=xiWq(s)∈Rdk,Wq(s)∈Rd×dkki(s)=xiWk(s)∈Rdk,Wk(s)∈Rd×dkvi(s)=xiWv(s)∈Rdv,Wv(s)∈Rd×dv
其中,第t 个 token 的第s 个注意力头的输出表示为ot(s),共有h 个注意力头,所有向量这里用行向量表示。
可见,只要我们将输入至今的 token 的所有 key 和 value,并增量式地继续存储下去,那么每新来一个 token 我们都可以基于已有的结果继续计算(推理)下去,这就是 KV Cache。
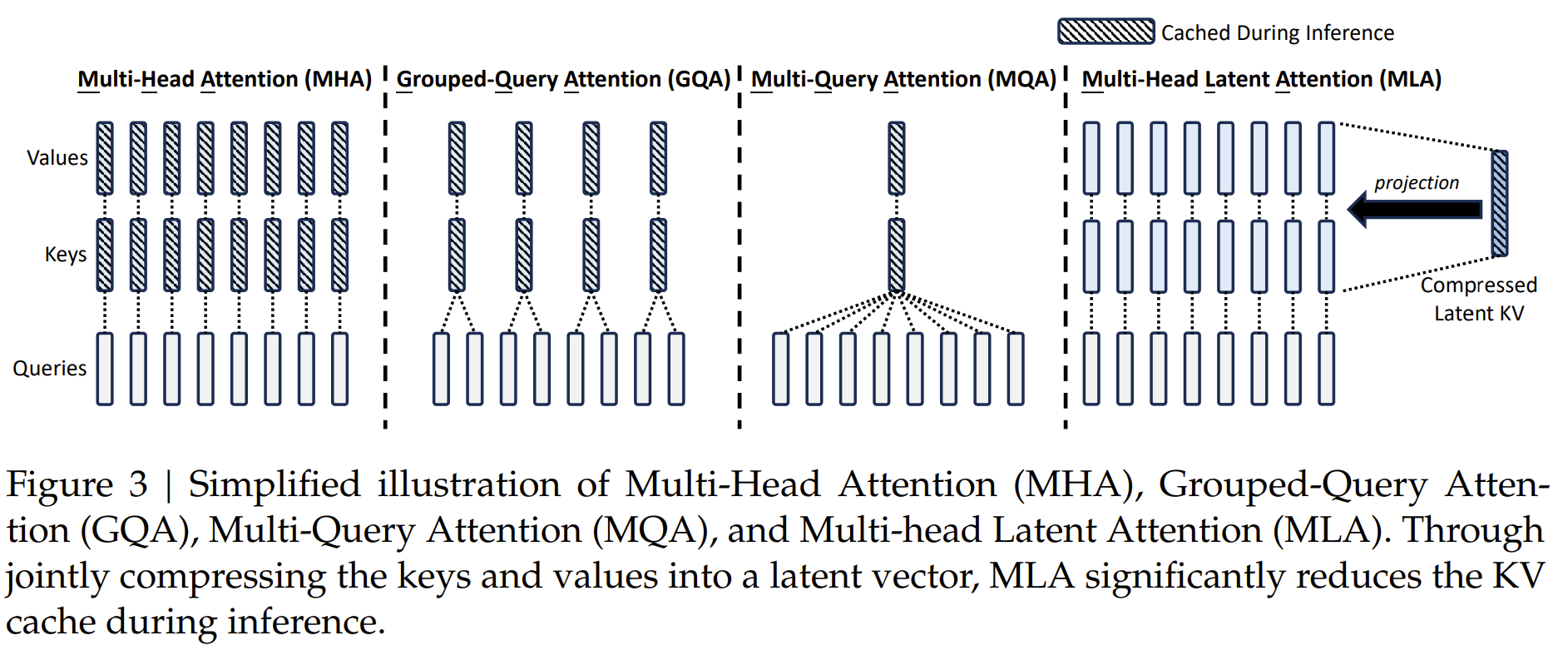
一个最直观的想法自然就是从所谓的“多头”中去优化,因为每多一个“头“就多一份参数Wk(s),Wv(s) 的存储。所以接下来我们要介绍的优化方案,包括 MQA、GQA、以及 DeepSeek v2 & v3 中使用的 MLA 都是在这个思路上继续的。
MQA
MQA (Multi-Query Attention),是减少 KV Cache 的一次非常朴素的尝试,在2019年首次在论文《Fast Transformer Decoding: One Write-Head is All You Need》 中被提出。
MQA的思路很简单,前面所给出的图示中也能够很明显地看出来,那就是直接让所有 Attention Head 都共享同一个K、V,用公式来说,就是取消 MHA 所有k,v 的上标(s).
很明显,MQA直接将KV Cache减少到了原来的1/h,这是非常可观的,单从节省显存角度看已经是天花板了。效果方面,目前看来大部分任务的损失都比较有限,且MQA的支持者相信这部分损失可以通过进一步训练来弥补回。此外,注意到MQA由于共享了K、V,将会导致Attention的参数量减少了将近一半,而为了模型总参数量的不变,通常会相应地增大FFN/GLU的规模,这也能弥补一部分效果损失。
GQA
MQA 对 KV Cache 的压缩直觉来讲确实有点严重,特别是h 较大的时候,可能会影响模型的学习效率以及最终效果。为此,一个 MHA 与 MQA 之间的过渡版本GQA(Grouped-Query Attention)应运而生,出自论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》.
GQA的思想也很朴素,它就是将所有 Head 分为g 个组(g 可以整除h),每组共享同一对K、V,如下列公式所示。
qi(s)=xiWq(s)∈Rdk,Wq(s)∈Rd×dkki(⌈sg/h⌉)=xiWk(⌈sg/h⌉)∈Rdk,Wk(⌈sg/h⌉)∈Rd×dkvi(⌈sg/h⌉)=xiWv(⌈sg/h⌉)∈Rdv,Wv(⌈sg/h⌉)∈Rd×dv
仍然以上面的示意图为例,图中h=8,g=4,所以就有h/g=2 个 Head 为一组。当s=1,2 时,上标⌈sg/h⌉=1,即他们俩被分为同一组,以此类推。在计算时属于同一组的 KV 是共享的。值得一提的是,当g=1 时 GQA 就退化成了 MHA,当g=h 时 GQA 就变成了 MQA。
虽然 GQA 的压缩率不如 MQA,但同时也提供了更大的自由度,效果上更有保证。
MLA
MLA(Multi-head Latent Attention)由 DeepSeek v2 的技术报告首次提出,报告里是从低秩投影的角度引入 MLA 的,而苏剑林苏神对 MLA 进行解读时,考虑到了 MLA 的另一个解释的视角(苏神认为这个视角可能更接近MLA的本质),即“MLA 是 GQA 的一般化形式”。
低秩压缩视角
DeepSeek 为了解决 KV Cache 问题进而引入了MLA,其核心想法是将k,v 联合起来,一并通过低秩投影压缩(由下投影矩阵Wc 完成,原论文中写作WDKV,Down-projection matrix)到某个潜在空间(Latent Space)中得到一个潜在KV向量c。
如果想要还原出k,v ,可以分别利用两个上投影矩阵(Up-projection matrices,原论文写作WUK 和WUV)作用到c 上以还原。具体来说 QKV 由下式给出。
qi(s)=xiWq(s)∈Rdk,Wq(s)∈Rd×dkki(s)=ciWk(s)∈Rdk,Wk(s)∈Rdc×dkvi(s)=ciWv(s)∈Rdv,Wv(s)∈Rdc×dvci=xiWc∈Rdc,Wc∈Rd×dc
GQA增强视角
回看 GQA 的核心做法:首先将向量对半分为两份分别作为K、V,然后每一份又均分为g 组,每组复制h/g 次,以此来“凑”够h 个 Attention Head 所需要的K、V。
实际上,分别针对 K 和 V 的g 个组进行线性投影(分别有g 个投影矩阵,共2g 个),等价于使用一次线性投影将 token 向量xi 投影生成出维度是g(dk+dv) 的新向量,然后再对新向量进行拆分,最后对每一份复制h/g 次。如果我们把最后这个复制的过程也替换成一般的线性变换,也就是再通过一次线性投影将维度是g(dk+dv) 的新向量投影成维度是h(dk+dv) 的新向量,然后再拆开成每一个 Attention Head 所需的 K、V。而这,其实就是 MLA 的处理方案,通过将分割、复制操作(可以视为某种更特殊而又简单的线性变换)替换成更一般的线性变换,以增强模型的能力。
更形式化一点,我们将上面的描述用公式表达,将 GQA 的所有g 个组的k,v 拼起来视作某个向量c 的话,就能得到:
ci∈Rg(dk+dv)[ki(1),⋯,ki(g),vi(1),⋯,vi(g)]=xiWc∈Rd×g(dk+dv)[Wk(1),⋯,Wk(g),Wv(1),⋯,Wv(g)]
由于dc=g(dk+dv)<d 的,所以这个过程就是一个低秩投影(而“复制”的过程就是一个上投影)。也就是说,其实 GQA 所做的事情,也是在做一个低秩投影!
事实上,MLA的本质改进不是低秩投影,而是低秩投影之后的工作,包括重新定义所需缓存的向量以及在新定义下如何处理 RoPE 的问题。
矩阵参数的吸收化简
如前文所述,MLA 在低秩投影后通过不同的上投影矩阵(替换掉GQA的复制操作)增强了模型能力。但是这样一来,因为使用了不同的投影,所以 KV Cache 里我们仍然需要存储每个 Head 的k,v (大小又恢复成跟 MHA一样大了),这违背了GQA的初衷。为此,MLA 结合 Dot-Attention 的具体形式,通过一个简单但不失巧妙的恒等变换来规避这个问题。
我们知道计算注意力分数需要计算qk⊤,如果用 MLA 的投影策略将其写开:
qt(s)ki(s)⊤=(xtWq(s))(ciWk(s))⊤=xt(Wq(s)Wk(s)⊤)ci⊤
作者指出,我们可以把针对第s 个头的 key 的上投影矩阵Wk(s) 包含进前面针对 query 的矩阵Wq(s) 里面去,也就是把Wq(s)Wk(s)⊤ 这个整体看作是 Q 的投影矩阵,这样一来这一步的计算可以化简为qt(s)c⊤ (理论上只有在无限精度下这种合并才能成立)。
而针对第s 个头的 value 的上投影矩阵Wv(s) 实际上也可以合并到注意力层的输出层的投影矩阵里去(得到ot=[ot(1),ot(2),⋯,ot(h)] 之后通常还要再过一层线性层得到输出)。
所以总的来说,在 MLA 中我们实际只需要存储c 即可。注意到c 其实是没有上标的,也就是它与 Head 的数量无关,从这个角度上来说 MLA 实现了和 MQA 一样的压缩缓存量。
RoPE的解耦
参考
- 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces



