Graph Foundation Model | 能否在非欧世界涌现智能?
前言
在人工智能的发展历程中,基础模型(Foundation Models)的出现标志着机器学习范式的根本性转变。通过在海量数据上进行大规模无监督或自监督预训练,基础模型在自然语言处理(NLP)和计算机视觉(CV)领域展现出了卓越的零样本(Zero-shot)泛化能力和涌现能力(Emergent Capabilities)。
然而,现实世界中存在大量以非欧几里得空间结构存在的数据,如社交网络、生物大分子结构、知识图谱、推荐系统网络以及城市时空基础设施网。长期以来,深度图学习(Deep Graph Learning)范式主要依赖于针对特定任务、特定数据集的端到端训练。这种传统的图学习范式虽然在单一基准上取得了成功,但存在显著的局限性:模型缺乏跨域迁移能力,且在面临数据稀缺或新出现的图拓扑结构时表现出严重的脆弱性。
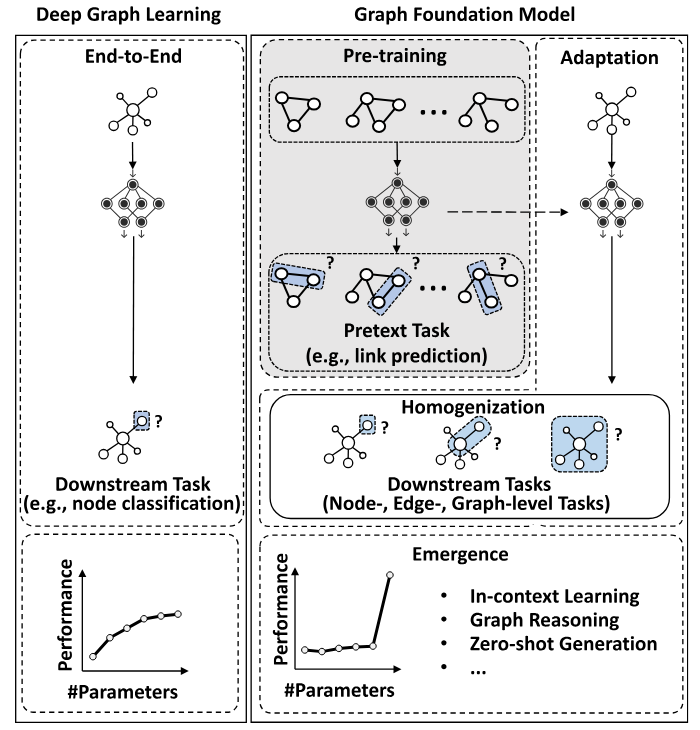
图基础模型(Graph Foundation Models, GFMs)的提出正是为了打破这一局限。其核心愿景是实现深度图学习的“同质化”(Homogenization)与“涌现性”(Emergence)。
- 同质化:一套统一的模型架构和训练方法能够适用于多源异构的图数据,从而消除为每个新图数据集构建独立模型的冗余工作;
- 涌现性:模型在参数规模和预训练数据达到一定量级后,能够隐式地推导出未直接编程的结构化推理与泛化能力。
核心泛化挑战
传统的GNNs 和 Graph Transformer(GTs)在跨域应用时面临着阻碍模型泛化的三大核心异质性问题:
特征异质性
在不同的应用领域,图数据中节点和边的特征空间存在天壤之别。
- 在分子图中,节点代表原子,其特征通常是低维的物理化学属性(如原子序数、电荷数、化学键类型);
- 在学术引文网络或电子商务推荐图中,节点代表论文或商品,其特征往往是高维的文本词袋向量(TF-IDF)或深度文本嵌入。
传统的GNN要求输入特征具有固定的维度,这使得在分子图上训练的模型无法直接应用于推荐系统。图基础模型通过特征对齐机制(如自然语言描述转换或跨模态投影),致力于将不同来源的异构特征映射到一个统一的隐式语义空间中。
结构异质性
图的拓扑结构在不同网络中表现出极大的差异。
部分网络(如社交网络)具有高度的小世界效应(Small-world effect)和长尾分布(Scale-free property),而其他网络(如规则的晶体结构或交通网)则呈现出更均匀的度分布和严格的几何约束。
图基础模型需要具备跨越不同拓扑结构的泛化能力,确保模型在密集的知识图谱上学习到的高阶关系推理能力,能够无缝迁移到高度稀疏的异常检测交易网络中。
任务异质性
传统的图机器学习将任务严格划分为节点级任务(如节点分类)、边级任务(如链路预测)和图级任务(如全图属性预测)。不同级别的任务通常需要不同形式的读出层(Readout functions)和损失函数,导致模型结构无法通用。
图基础模型旨在通过统一的提示范式(Prompting paradigm)或指令微调(Instruction tuning),打破这些物理界限,使得单一模型能够同时响应节点、边和图级别的任意自然语言指令。
技术路线与架构分类
为了应对上述三大异质性挑战,研究界在图基础模型的骨干网络设计、预训练策略以及下游自适应机制上进行了深刻的技术革新。现有的技术路线根据其对图拓扑与语义特征的建模侧重点,可系统地分类为三大主要阵营:基于图神经网络(GNN-based)、基于大语言模型(LLM-based)以及混合架构(Hybrid GNN+LLM)。
以下总结了当前主流图基础模型底层架构的分类对比:
| 架构类别 | 核心机制与代表框架 | 优势 | 局限性与挑战 |
|---|---|---|---|
| GNN-based | 以DeepGNNs或GTs为底座。通过对比学习或掩码自编码器在海量无标注图上预训练。代表为GraphPFN。 | 具有极强的图拓扑结构归纳偏置(Inductive Bias),在分子属性预测等长程结构交互任务中表现优异。 | 难以处理富文本属性节点,对高维语义的推理能力较弱;随着网络加深易出现过平滑(Over-smoothing)问题。 |
| LLM-based | 将图拓扑序列化(Tokenize)或展平为自然语言描述序列,直接利用预训练LLMs进行零样本推理。代表为InstructGLM。 | 具备强大的常识推理和语义理解能力,能够无缝融合多模态知识和文本属性,降低了标注数据的依赖。 | 丢失了高阶非欧图结构信息;自注意力机制的二次方复杂度使其难以处理数百万节点的大规模稠密图。 |
| Hybrid GNN+LLM | 结合GNN的结构感知与LLM的深度语义表达。典型方式为将GNN提取的结构嵌入作为前缀(Soft Prompt)注入LLM。代表为GraphGPT、OFA。 | 兼顾局部/全局结构与深度语义推理,在知识图谱问答、复杂推荐系统等复合任务中达到前沿性能(SOTA)。 | 模型参数量极其庞大,训练成本高昂;图特征空间与文本语义空间的结构对齐(Structural Alignment)仍存在巨大瓶颈。 |
预训练范式
预训练是图基础模型获取可迁移结构知识的核心环节。主流范式主要包含对比式预训练和生成式预训练两种路径:
对比式预训练(Contrastive Pre-training):旨在通过最大化正样本对(如同一节点或子图的两种不同增强视图)之间的互信息,同时最小化负样本对的相似度,来学习不变的图表示。这种方法在处理跨域异质图和提升节点级表征的鲁棒性方面具有显著优势。
生成式预训练(Generative Pre-training):通过重构图的结构或特征属性来学习底层分布。传统方法包括图掩码自编码器(Masked Autoencoders)。而在LLM时代,研究者引入了图级别的“下一个词预测”(Graph-level Next-Word Prediction)、图指令生成等复杂生成任务,以增强模型对结构上下文的连贯理解。
下游自适应机制
模型预训练完成后,需要通过自适应机制迁移到特定下游任务。除了传统的全参数微调(Fine-tuning)外,GFMs越来越多地采用图提示学习(Graph Prompting)和上下文学习(In-Context Learning, ICL)。
在图提示中,可学习的提示向量或结构化的提示图被注入到输入空间中,引导预训练模型将冻结的常识重定向到新的数据分布中,从而实现高效的零样本(Zero-shot)或少样本(Few-shot)推理。
图基础模型的具体方案深度剖析
为了具象化图基础模型的技术路线,有必要对近年来在跨域泛化和指令推理方向最具代表性的具体模型进行深度拆解。
1. OFA (One-for-All):跨域特征空间的自然语言统一
OFA架构的核心创新在于提出了一种完全基于文本属性图(Text-Attributed Graphs, TAGs)的统一图提示范式,旨在用单一的通用图模型解决来自不同领域、具备完全不同特征维度的图学习问题。
为克服特征异质性,OFA首先摒弃了传统的数值特征矩阵,转而使用自然语言系统性地描述不同域图中的节点和边属性。无论是引文网络中的论文摘要,还是分子图中的原子物理化学属性,所有任务特定的信息都被转化为结构化的文本字符串。随后,框架通过冻结的语言大模型(如Sentence-BERT)对这些跨域文本进行编码,从而确保所有图数据被强制映射到同一个共享的高维特征嵌入空间中。
在解决任务异质性方面,OFA引入了“兴趣节点”(Nodes-of-Interest)和图提示子结构(Prompting Substructures)的概念。在执行任务时,模型将一个特定的提示节点(Prompt Node)通过边连接到目标图中的相关节点上。信息在提示节点和目标图的所有节点之间进行图消息传递(Message Passing),最终系统直接提取提示节点的输出表征输入解码器进行预测。这种设计使得OFA在不改变底层图神经网络架构的情况下,成功实现了多领域的零样本和少样本学习泛化。
2. PRODIGY:赋能图网络的原生上下文学习
上下文学习(In-context Learning)是大语言模型的一项颠覆性能力,允许模型在不进行任何参数梯度更新的情况下,通过在输入提示中提供少量示例来适应新任务。然而,非欧几里得的图结构阻碍了这一机制的应用。PRODIGY首次打破了这一壁垒,提出了在复杂图网络上进行预训练与上下文推理的统一框架。
PRODIGY的核心机制是提示图表征(Prompt Graph Representation)。它将传统的零散示例(Prompt Examples)和查询(Queries)连接起来,构建成一个逻辑上的扩展图。在这个扩展图网络中,原始的输入节点/边与额外引入的“标签节点”(Label Nodes)相连,从而赋予了图表征更强的表现力。
配合提示图,PRODIGY设计了一种创新的图神经网络架构进行任务图消息传递(Task Graph Message Passing)。在推理时,标签信息可以经由消息传递机制,从示例节点的局部特征流向全局查询节点的表征中。研究表明,相比于纯自然语言提示,这种图结构的硬约束极大地限制了生成的多义性,使得在引文网络分类、知识图谱补全等完全未见过的图谱上,其零样本推理的准确率远超传统的对比学习基准。
3. GraphGPT:图结构与大语言模型的双阶段指令微调
作为混合架构的前沿探索,GraphGPT致力于将图领域特有的局部拓扑知识完美对齐到大语言模型的语义推理空间中。
GraphGPT的技术亮点在于其提出的双阶段图指令微调(Dual-Stage Graph Instruction Tuning)范式:
第一阶段(自监督图结构指令微调):在此阶段,模型提取图结构信号(如节点度、最短路径、中心性特征),并将其转化为自监督的图结构预测任务及自然语言指令。通过文本-图接地(Text-Graph Grounding)和轻量级的图文对齐投影器(Alignment Projector),LLM被注入了图领域的拓扑理解能力,学会了如何“阅读”并理解嵌入在几何空间中的上下文信息。
第二阶段(任务特定指令微调):在赋予模型结构感知能力后,第二阶段输入针对特定图下游任务(如节点分类或图问答)的高度格式化指令。进一步微调迫使LLM的输出适应图任务的专用格式。
为了提高模型在面对分布偏移时的推理准确度,GraphGPT还创新性地整合了思维链(Chain-of-Thought, CoT)蒸馏技术。通过显式建模图网络中的思想流和多跳推理步骤(例如从图的局部邻居出发,逐步逻辑推导至全局连通分量),语言模型在生成答案时的连贯性和逻辑一致性得到了显著增强。
4. GraphPFN:面向合成图的先验数据拟合网络
尽管OFA和GraphGPT高度依赖语言模型的语义先验,GraphPFN则另辟蹊径,首次将表格数据领域大获成功的先验数据拟合网络(Prior-data Fitted Network, PFN)框架扩展到图学习领域。
面临公开图数据集规模小、异质性强的问题,GraphPFN在预训练阶段完全抛弃了真实世界的图数据。相反,它利用随机块模型(Stochastic Block Models)和优先连接过程(Preferential Attachment Process)等数学生成器,动态构建了海量、具有不同拓扑属性的合成图(Synthetic Graphs),并利用图感知的结构化因果模型生成属性特征。
在模型架构上,GraphPFN将注意力图邻域聚合层(Attention-based Graph Neighborhood Aggregation Layers)注入到Tabular Foundation Model(如LimiX)中。通过这种机制,模型被训练为在一个前向传播(Forward Pass)周期内,直接在上下文中处理全套训练示例并输出预测。实验证明,在包含多达5万个节点的真实多样化图数据集上,GraphPFN展现出了强大的上下文学习能力,在完全不进行权重微调的情况下,即可达到甚至超越从头开始训练的任务特定GNN的性能。
实验设计与评估基准(Benchmarks)
随着图基础模型底层架构的成熟,学术界对其能力的评估已经从单一数据集的同分布监督学习,全面转向强调跨域迁移(Cross-domain Transfer)、零样本(Zero-shot)、少样本(Few-shot)和分布外泛化(OOD Generalization)能力的综合测试。构建并执行严谨的实验协议是衡量GFM价值的核心。
综合评估基准套件
为打破不同领域图数据评估标准支离破碎的困境,研究界开发了多个统一测试平台以规范化实验流程:
GFMBench:作为一个开源的全链路标准化评估管道,GFMBench将底层模型实现与具体业务逻辑彻底解耦。它标准化了从数据预处理、模型预训练、到分布外零样本推理的全部流程。在生物医学领域,GFMBench甚至集成了基因组基础模型(Genomic Foundation Models)的评估,例如通过评估序列嵌入之间的余弦相似度(Cosine Similarity),以及利用AUROC/AUPRC指标量化致病变异的影响,实现了不同图模态评估指标的统一。
GraphBench:作为填补现有评估短板(如OGB过于集中在小分子化学图)的下一代测试套件,GraphBench大幅拓展了评估场景。实验域涵盖了算法逻辑推理、芯片设计网络、组合优化图、SAT求解预测、社会网络分析以及大规模天气预报网。该基准系统支持节点级、边级、图级以及生成式任务,并提供标准的分布外评估拆分,为对比图Transformer和现代消息传递神经网络(MPNNs)提供了基石。
实验数据分布与核心验证任务
为了全面验证模型能力,图基础模型通常需要在以下几类核心数据集与场景中开展广泛的实验测试:
| 数据域类别 | 代表数据集与场景 | 核心评估任务设计 | 零样本/少样本能力测试重点 |
|---|---|---|---|
| 文本属性图 (TAGs) | OAG-CS, arXiv citation, DBLP | 节点级分类、学术话题联合搜索、作者相关性推荐 | 跨域零样本迁移测试:评估在OAG(学术网)上预训练的特征,能否在不更新梯度的情况下,直接应用于IMDB(电影领域)等异构图的节点分类并取得合理性能。 |
| 分子与生化网络 | MoleculeNet, 蛋白质互作网(PPI) | 图级属性回归、分子毒性/溶解度预测、细胞信号传导图分析 | 评估模型在处理极度不规则结构和复杂化学键特征时的泛化能力,以及通过自然语言指令预测化学属性的准确性。 |
| 知识图谱 (KGs) | Wiki, FB15K-237, ConceptNet, NELL | 关系三元组抽取、复杂链路预测、常识知识图谱补全 | 评估大语言模型结合结构特征后,能否利用其内部的世界常识,弥补高度稀疏知识图谱的连接缺失。 |
| 动态与时序图 | Llm4dyg基准, 交通流时序数据 | 随时间演化的边预测、动态异常检测、因果结构外推 | 评估模型捕获图拓扑随时间戳演变的动态关联性,及其对时序分布偏移的抵抗能力。 |
在这些严苛的基准下,优秀的图基础模型能够验证其涌现能力。例如,通过引入<think>和<rethink>奖励建模(Reward Modeling),结合直接策略优化(GRPO)强化学习的图模型,在面临节点分类和链路预测时,能够输出连贯且多向比较的中间推理路径,从而在未见过的域上实现SOTA级别的零样本性能。
现有算法的不足与未来技术挑战
尽管图基础模型在跨域泛化和指令推演方面取得了突破性进展,但其发展仍处于早期探索阶段。在迈向全面通用人工智能的道路上,现有算法体系依旧面临多维度的严峻挑战:
1. 结构对齐与模态融合鸿沟(Structural Alignment)
LLM和GNN在处理信息机制上存在本质冲突。LLM擅长处理基于一维序列和词元(Tokens)特征捕捉的欧几里得距离逻辑,而图结构包含了高度非欧几里得、排列不变且不规则的关系语义。在当前的混合架构(Hybrid GFM)中,简单地将图节点特征拼接或线性投影为LLM的输入词元,往往会导致图高阶拓扑信息的丢失或对文本语义的过拟合。突破这一鸿沟,亟需开发出能够真正理解子图同构性、循环结构以及空间特征不变性的原生图文多模态对比学习新范式。
2. 计算可扩展性困境(Scalability & Computational Complexity)
现实世界中的图结构(如全球社交网络、超大型金融交易图)往往包含数亿甚至数十亿级节点和边。然而,旨在捕获全局图感受野的图Transformer(Graph Transformers)与自注意力多模态LLM,其计算复杂度和内存消耗均随节点数量或序列长度呈二次方()爆炸式增长。尽管现有的图学习技术(如子图采样或GraphSAGE机制)能缓解局部计算压力,但在自回归大模型中集成此类全局注意力仍然存在算力瓶颈。截至目前,业界依然缺乏一种能在保证全局拓扑感知的同时,在十亿节点规模下保持线性时间复杂度的规范化“大图模型”底座。
3. 高质量开源数据的稀缺与异质分布偏移
与互联网上海量的纯文本或图像预训练语料形成鲜明对比,高质量、涵盖多样化图结构(如同构、异构、超图、动态时序图)的开源公共图数据集极为稀缺,且往往局限于特定的小众领域(如单纯的引文网络或分子数据)。这种数据偏差导致现有GFM极易在特定领域过拟合。当模型应用于完全不同结构分布的领域(如具有极度长尾度分布和长程依赖的欺诈洗钱交易网络)时,模型的泛化性能常常因分布外(OOD)问题而暴跌。
4. 混合专家机制(MoE)的路由效率瓶颈
为了处理特征和结构的极端异质性,一些前沿的图基础模型引入了混合专家(Mixture-of-Experts, MoE)架构,试图为不同的子图或节点特征动态分配最适合的专家网络。然而,深入的实验表明,MoE架构在图学习中的路由分配效率尚未得到充分发掘;研究发现,路由器分配的排名第一的专家其性能有时甚至不及第二或第三排名的专家。直接对多个图专家进行集成推理会带来难以承受的计算开销,而普通的专家融合策略则会导致性能次优。如何在图结构上实现知识蒸馏启发的行为对齐,仍是一个巨大的技术盲区。
结语
图基础模型(GFMs)的崛起不仅是机器学习在非欧几里得空间数据处理技术上的里程碑,更标志着结构化关系推理迈入了通用人工智能时代。从打破特征与任务异质性的OFA,到赋能图原生上下文学习的PRODIGY,再到通过指令微调和大规模合成先验实现逻辑推理的GraphGPT与GraphPFN,基础大模型的底层逻辑已经被成功复刻并升华至图学习领域。尽管在多模态架构的绝对对齐、数亿级节点计算扩展性、以及高质量预训练语料体系建设上仍横亘着多重技术鸿沟,但其基于提示工程的零样本迁移泛化能力,已被大量严苛的交叉基准测试所证实。
更深远的是,将图基础模型的空间认知能力与多模态时空架构(STFMs)相融合,为构建认知级“城市大脑”指明了一条变革性的通途。无论是通过随机多模态融合技术抵御数据稀疏性的UrbanFusion,还是彻底打通城市宏观预测与微观检索计算范式的UrbanSparse系统,城市大模型都在不断拓展智能决策的物理边界。随着算力基建的迭代和大规模混合专家路由算法的成熟,由图基础模型支撑的多模态泛化人工智能,必将在未来的智慧交通、药物研发乃至复杂系统的宏观演化中,发挥出不可估量的价值与潜力。