
可解释性Ⅱ:事前解释的可干预 Concept Bottleneck Net.
前言
在机器学习的可解释性研究版图中,我们曾经介绍过包括 SHAP 和 LIME 等在内的事后解释方法(Post-hoc Explanations),它们基本上都是通过量化输入对输出变化的影响 以解释模型的决策。
然而这类后解释的方法存在局限性(以图像分类为例进行说明):
- 只解释相关性,不解释因果性:归因方法可能告诉你模型关注了“草地”,于是最终把图片分类为“狗”,但中间缺乏因果关系。
- 无法干预(Non-intervenable):如果你发现模型关注了错误的特征(比如图片水印),你除了清洗数据重训模型外,束手无策。
- 缺乏语义:热力图(Saliency Map)只是一堆高亮像素,它不能告诉你模型是否真的理解了“耳朵”或“尾巴”。
于是,一种在事前进行解释的方法Concept Bottleneck Models (CBMs) 应运而生。不同于在模型训练完后去猜测模型在想什么,CBMs 是在模型架构内部强行插入人类的认知逻辑。
CBM
Title:Concept Bottleneck Models (ICML 2020)
Link:https://arxiv.org/abs/2007.04612
Concept Bottleneck Models 的核心思想非常简单:在原始输入和最终输出之间强制插入一个人类可理解的概念层(Concept Layer)。想象一位经验丰富的医生诊断疾病的过程:首先观察病人的症状(发烧、咳嗽、皮疹),然后基于这些症状做出诊断。CBM正是模拟这种人类决策过程,将复杂的感知数据转化为高级概念,再基于这些概念进行推理。
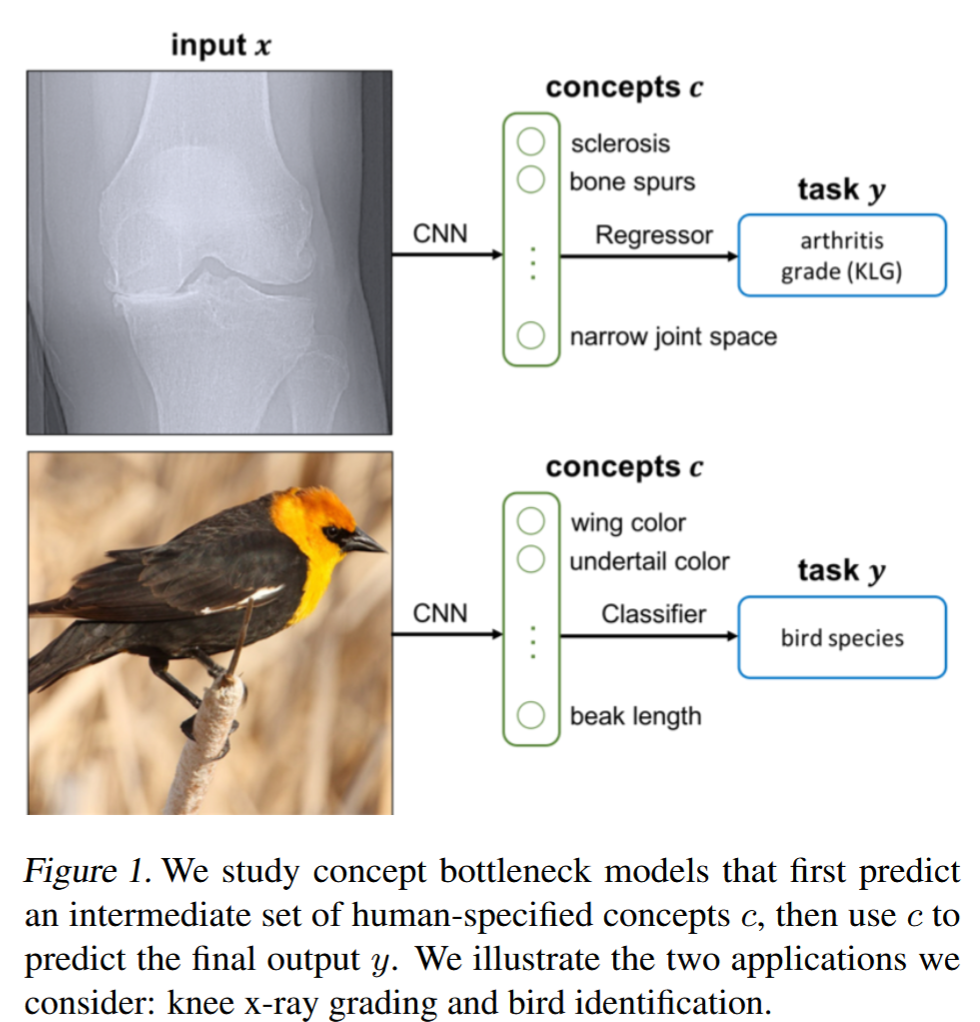
核心原理
具体来说,CBM的架构分为两个关键阶段:
- 概念预测阶段:将原始输入 映射到人类定义的概念空间,其中 是 concept 的个数。该部分由深度神经网络(如 ResNet)负责,从像素中提取预定义的概念(如“翅膀颜色”、“喙长”)。
- 任务预测阶段:基于预测的概念 做出最终任务决策. 该部分由一个简单的线性层或浅层MLP 负责,基于概念做决策。关键约束在于: 的输入只能是概念,不能直接接触。这就是“瓶颈(Bottleneck)”。
CBM的两阶段方法不仅让推理过程透明了,更重要的是实现了测试时干预(Test-time Intervention):在推理时,如果用户发现某个概念预测错误(如专家认为输入图像的小鸟的冠羽其实是橙色而不是模型给出的红色),可以手动修正该概念值,模型会基于修正后的概念重新进行预测。
训练范式
论文还系统性地比较了三种训练 CBM 的方法:
A. 独立训练 (Independent Training)
将模型切断,互不干扰地训练两部分。
- 利用数据集 训练:
- 利用数据集 训练:
- 特点: 在训练时看到的是完美的真实概念。
- 缺点:推理时,输入给 的是预测出的概念(带有噪声)。这种“训练-推理分布不一致”会导致性能较差。
B. 顺序训练 (Sequential Training)
为了解决独立训练的分布不一致问题:
- 先独立训练。
- 利用训练好的 生成预测概念。
- 利用数据集 训练。
- 特点: 学会了如何处理 产生的噪声。
- 缺点: 的训练完全不看最终任务,可能提取不到对 最关键的特征细节。
C. 联合训练 (Joint Training) —— 论文推荐方法
同时优化两个目标,允许误差反向传播穿过瓶颈。
损失函数为加权和:
其中, (Lambda):这是一个关键超参数。
- 如果 很大:模型被强迫先学好概念。
- 如果 很小(甚至为0):模型退化为黑盒,中间层虽然叫“概念层”,但可能编码了人类看不懂的信息。
Joint Training 是精度最高的方法,因为 会为了 的准确性而微调概念的表示。
实验结论
论文在两个数据集上进行了详尽实验:
- CUB (Caltech-UCSD Birds-200-2011):鸟类分类,包含 312 个细粒度属性(如喙长、翅膀颜色)。
- OAI (Osteoarthritis Initiative):膝关节 X 光片,用于诊断关节炎等级,包含临床概念(如骨刺、硬化)。
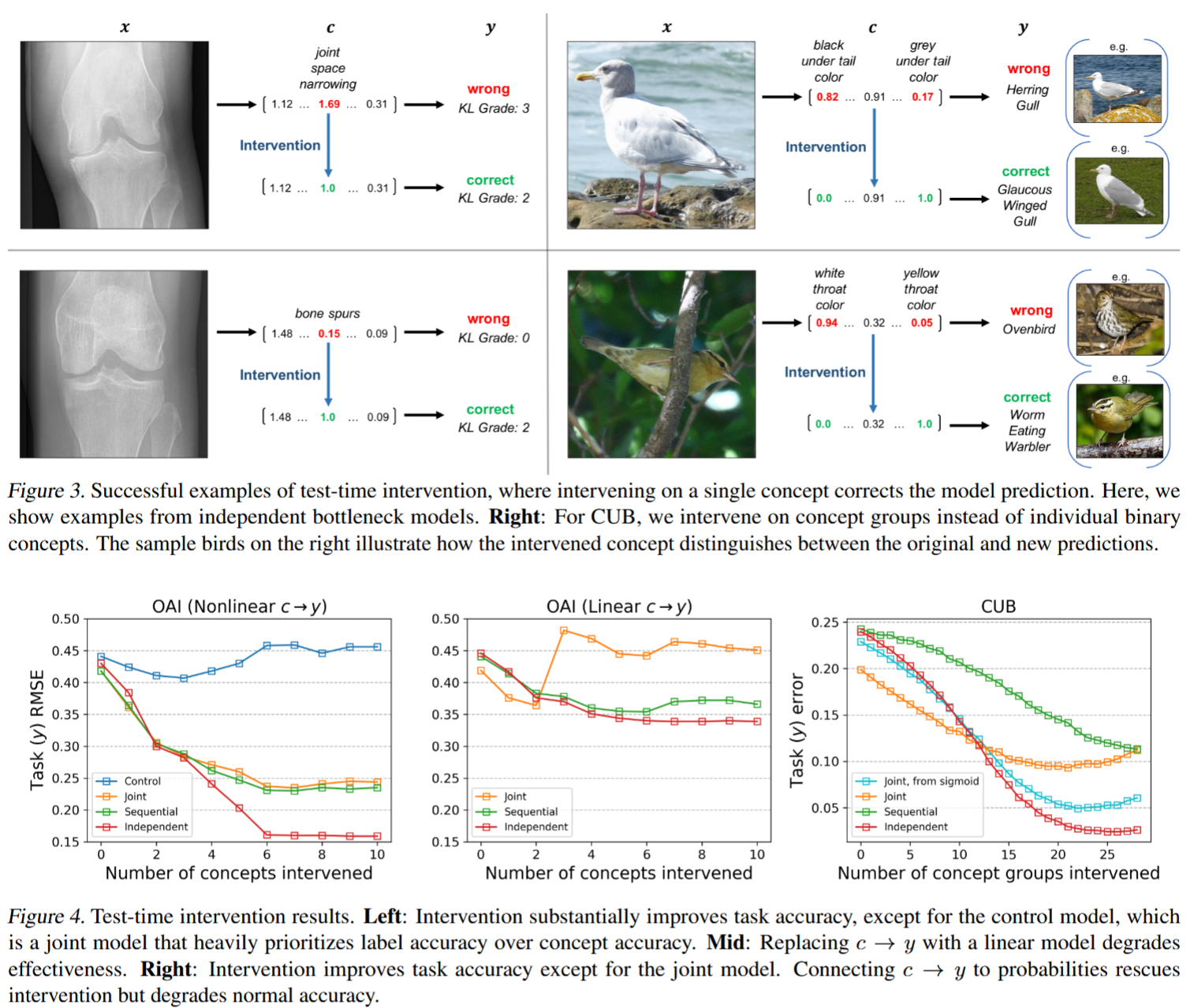
结果显示,CBM 存在精度损失的问题,即相比传统的方法(Standard ResNet,即黑盒),因为 CBM 强行将高维图像压缩成几十个标量,这必然会丢失大量用于分类的非结构化信息,从而产生 Information Bottleneck。
另一方面,实验证明了虽然 CBM 的初始精度低,但只要人类介入一点点,CBM 就有机会反超黑盒。
CEM
Title:Concept Embedding Models: Beyond the Accuracy-Explainability Trade-Off (NeurIPS 2022)
Link:https://arxiv.org/abs/2209.09056
传统 CBM 强行将每个概念压缩为单一标量概率。这导致了严重的信息丢弃(例如,“翅膀”这个概念除了“有无”,还包含颜色、形状、纹理等辅助分类的信息,但标量无法承载)。
Concept Embedding Models (CEM) 认为,如果让每个概念以高维向量(Embedding) 的形式存在,那就能保留足够的特征信息给下游任务(保住精度),又能通过数学约束确保这些向量与人类语义对齐(保住解释性)。
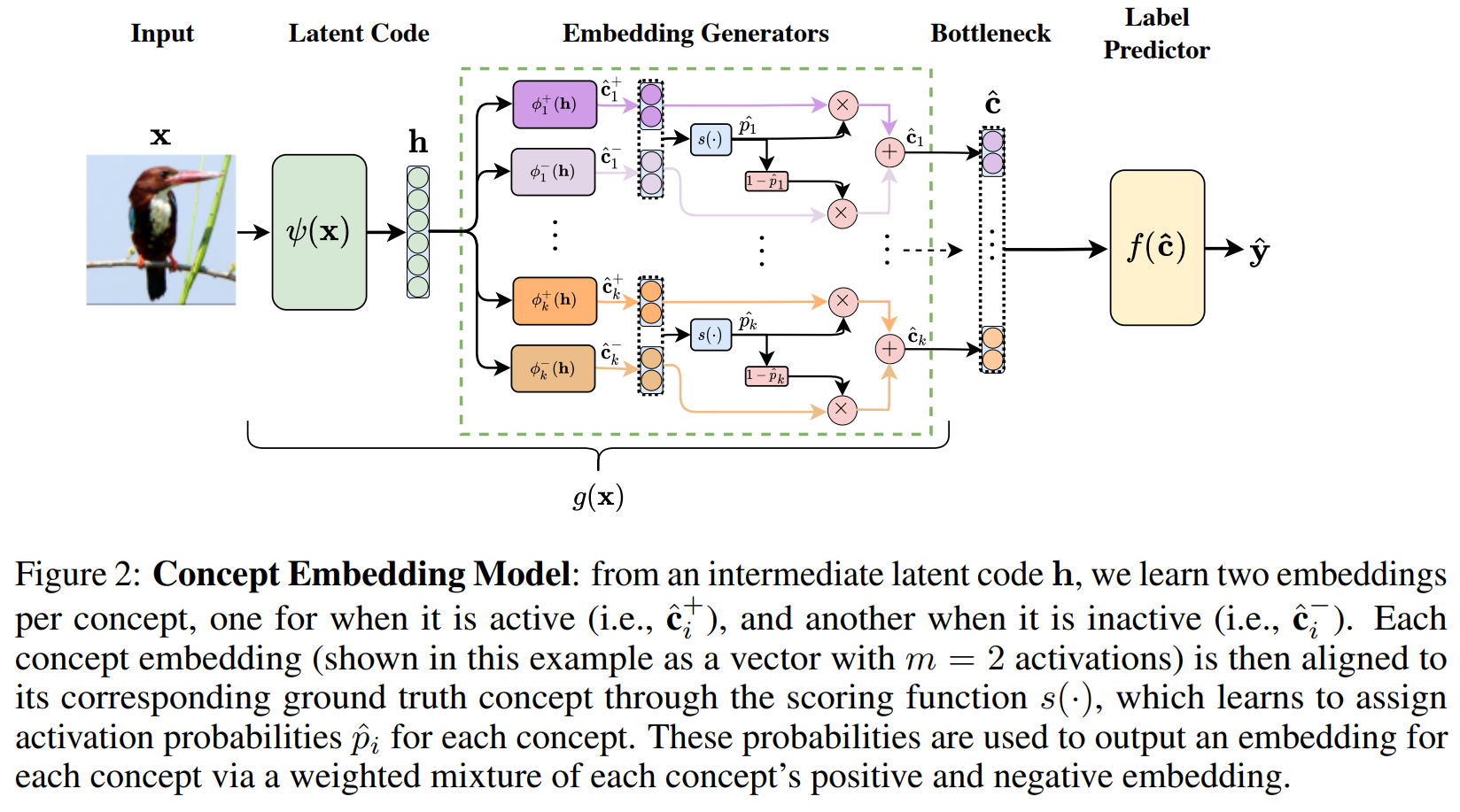
状态向量
假设一共要预测 个概念。对于每一个概念,模型学习两个可训练的嵌入向量(Embeddings):
- :代表该概念存在时的特征(Active state)。
- :代表该概念缺失时的特征(Inactive state)。
这些向量的维度为(通常为 8 或 16),通常是由输入 在 Latent Space 的 Representation 进行线性映射 得到。
所有概念得到的正负状态向量都通过同一个(共享参数)评分网络 生成概念 发生的概率。请注意,这里的概率才是对应 CBM 中的第 个概念的标量预测值。
进而再通过此概率的加权求和得出该概念最终的concept embedding 概念嵌入:
最终下游的标签预测器 接收到的是一组向量序列。整个前面的处理过程还可以表示为.
正如前面所说,所有 个概念的发生概率 才对应着 原版CBM的概念,而 CEM 也以此为训练目标,最终有:
RandInt
CEM 论文还提出了一个非常重要的训练技巧——RandInt (Random Intervention Training)。
在训练过程中,模型会随机选择一部分概念,强行将其预测概率 替换为真实的标签。这模拟了测试时的干预行为,强迫下游的分类器 学会:“如果人类修正了某个概念,我必须根据修正后的向量做出响应。”,以提高了模型的干预效率(Intervention Efficiency)。
具体来说,模型预测的某个概率 会以 的概率随机替换成 ground-truth 真值,从而模型的概念嵌入
作者将这种做法类比为 dropout,因为一部分 concept embedding 仅使用来自其概念标签的 feedback 进行训练,而另一部分则同时接受来自其概念和任务标签的feedback。
概念对齐分数 CAS
在 CEM 中,由于我们将概念从简单的“标量概率”提升到了“高维向量嵌入”,这会产生了一个合理的担忧:这些向量是否还会忠实地代表人类定义的语义?
例如,如果一个代表“翅膀”的向量序列里偷偷编码了“眼睛”的信息,那么这种解释性就是虚假的。概念对齐分数 (Concept Alignment Score, CAS) 就是为了量化这种纯度而设计的评估指标。

在 CEM 的原论文中主要是利用”聚类与真实分类是否对齐“来量化的。以所有样本的第 个概念嵌入 对样本进行聚类,然后对比这些样本的真实标签下的分类情况。当然实际上还可以用线性探测、互信息等策略。
实验说明,CEM 不仅能够保证较高的准确率,也能保持概念可解释性的纯度(保持在图中的右上角)。
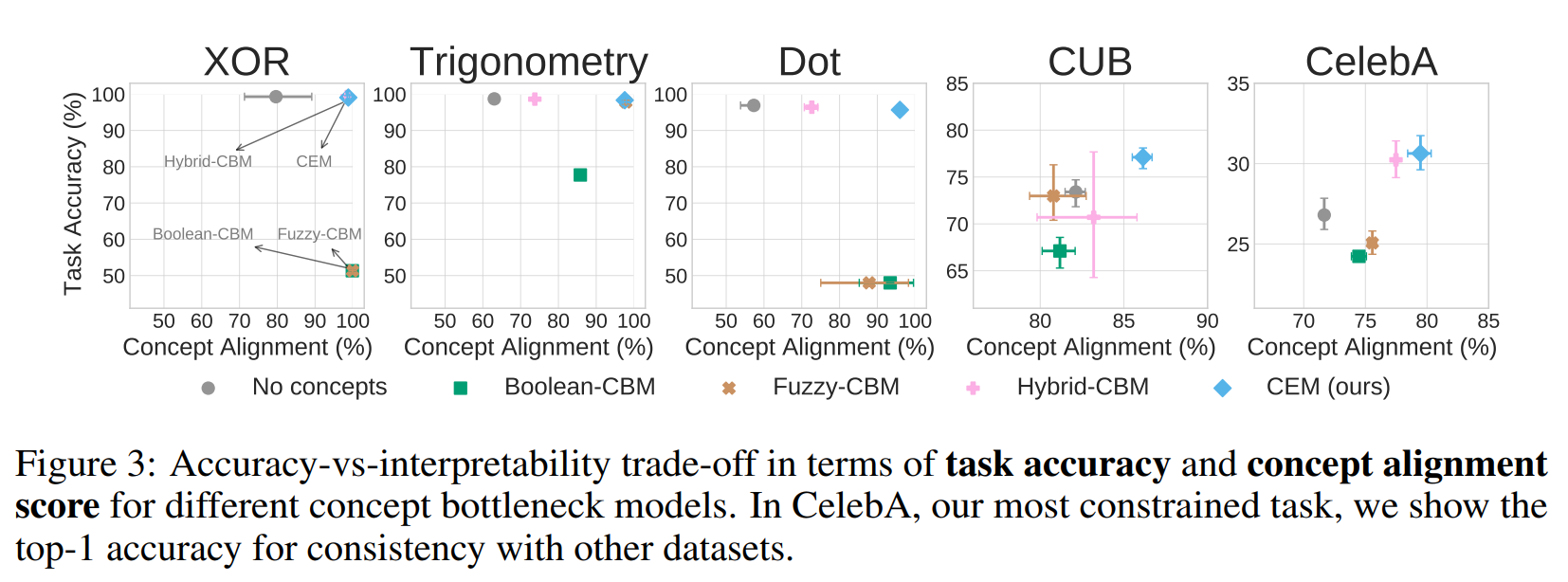
信息瓶颈
作者基于信息论进一步研究了 information bottleneck,推测基于 embedding 的 CBM 通过充分保留来自于输入分布的信息来避免发生information bottleneck,即概念嵌入 与输入 直接的互信息 较高;而 scalar-based concept representations 会被迫在 concept 层面压缩来自输入的信息,从而造成了信息瓶颈。
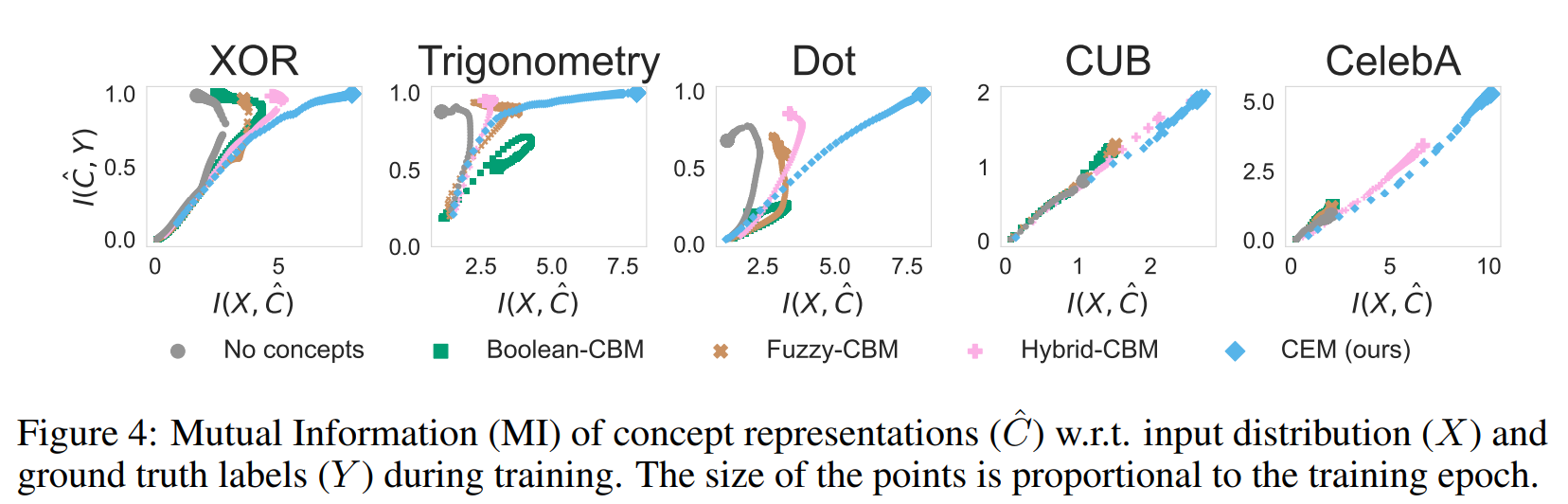
实验也表明,CEM 的嵌入在保留了更多输入信息的同时也能有较高精度的输出。此外关于 IB 和 CAS 的平衡,通过实验可以总结出如下特性:
| 状态 | 信息瓶颈 (IB) | 概念对齐 (CAS) | 结果 |
|---|---|---|---|
| (传统 CBM) | 极窄(丢信息) | 极高(纯净) | 精度低,解释性真。 |
| 适中 (CEM) | 宽窄适中 | 保持高位 | 精度高,解释性真(SOTA)。 |
| 过大 | 极宽(无损) | 显著下降 | 精度极高,但演变为黑盒。 |
Post-hoc CBM
Title:Post-hoc Concept Bottleneck Models (ICRL 2023)
Link:https://arxiv.org/abs/2205.15480
为了解决 CBM 精度低且模型需要重头训练的问题,Post-hoc CBM(PCBM) 又利用了“事后改造”的思路,直接拿一个预训练好的强大模型(如 CLIP, ResNet),通过“事后(Post-hoc)”手段,把它的特征空间映射到概念空间,并构建瓶颈。
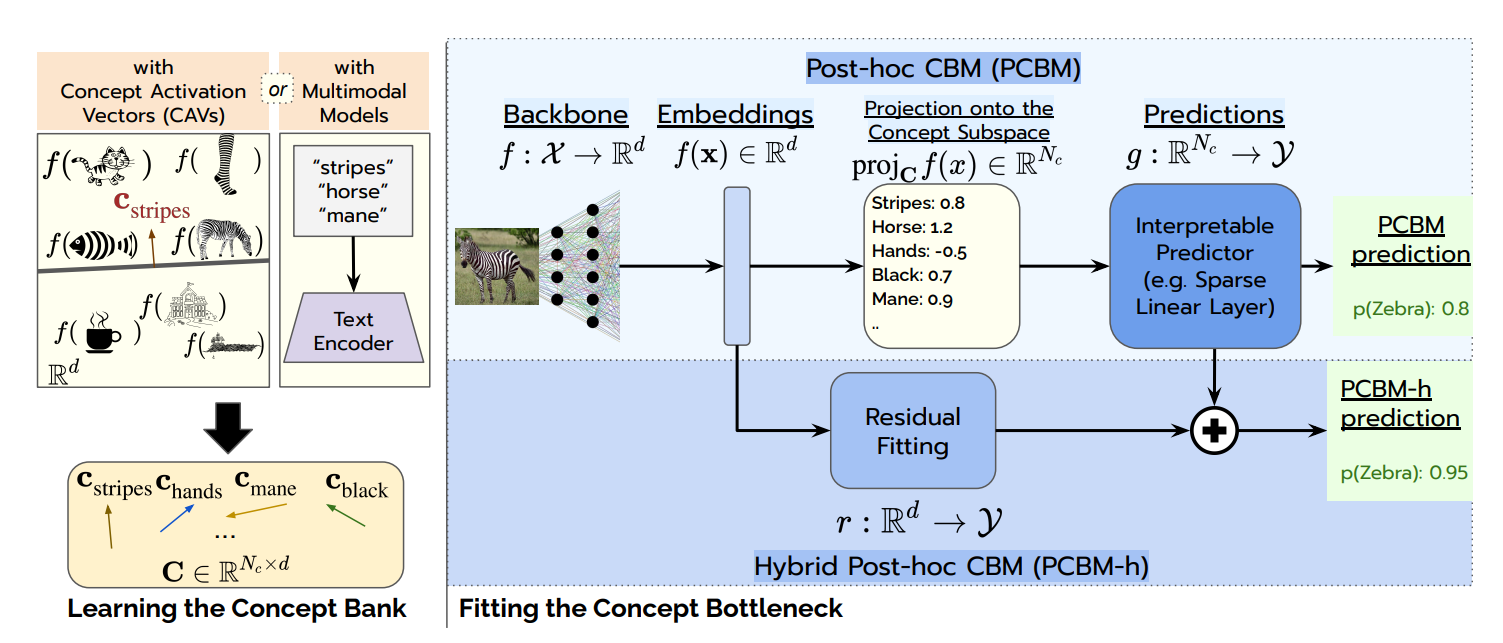
具体来说,PCBM 继承了 Concept Activation Vectors (CAVs) 的思想,直接截取预训练模型的中间特征层(通常是倒数第二层),然后将这一层从原来的空间投影到”概念空间“中,然后再从这个空间开始训练简单的 Predictor 应对下游任务,同时还可以辅以残差连接提升预测精度。
为此,我们必须先介绍一下 CAVs。
CAV
CAVs 由 Google Brain 的 Been Kim 等人在 2018 年的论文 《Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)》中正式提出。
CAV 的目标是量化一个用户定义的概念(例如“条纹”)对模型预测某个类别(例如“斑马”)的重要性,所以某种程度上 CAV 的原论文也是一种事后解释,更符合归因分析类的方法。
具体来说,假设我们有一个预训练好的模型,给定某一个中间层。给定一个输入样本,其类别为,它在 层的输出表示为。那么接下来 CAV 将通过以下步骤量化某个概念对其的影响:
A. 定义人类概念 (Defining the Concept)
为了定义一个概念(例如“条纹”),我们需要两组样本集:
- 正例集 ():包含该概念的图像(如一堆有条纹的贴图、斑马、斑马线)。
- 负例集 ():随机的一组不包含该概念的图像。
B. 训练线性分类器 (Concept Probing)
将这些图像输入模型,提取它们在 层的激活值:
- 正例激活集:
- 负例激活集:
我们训练一个线性二分类器(通常是线性 SVM 或 Logistic 回归),尝试在特征空间中将正例和负例分开。分类器的权重向量 决定了分割超平面。
概念激活向量 (CAV),记作,定义为分类器超平面的法向量(从负例指向正例的方向):
这个向量 在 层的特征空间中代表了“增加该概念语义”的方向。
C. 计算概念敏感度 (Conceptual Sensitivity)
现在我们要看这个概念对类别 的贡献。我们计算类别 的 Logit 分数 对隐藏层激活值 的梯度:
这个梯度代表了:特征空间中哪个方向的变化最能增加类别 的预测概率。
概念敏感度 定义为梯度与 CAV 的方向导数(标量积):
- 如果,说明增加“条纹”的概念会增加预测“斑马”的概率。
- 如果,说明该概念对该类别有负面影响。
单个样本的敏感度可能具有偶然性,因此作者提出了 TCAV (Testing with CAV),用于评估整个类别的全局重要性。
对于类别 的所有样本,统计其中敏感度为正的比例:
- TCAV 分数。
- 例如:如果,说明对于 80% 的斑马图片,“条纹”这个概念都对分类有积极贡献。
概念库 (Concept Bank)
PCBM 和 TCAV 一样,考虑多种人类概念,最终得到一组概念方向 组成概念基(Concept Basis)。
值得注意的是,论文提出了两种获取概念向量 的方法:
- 基于验证集 (Validation-based):如果有少量带概念标注的数据,参考 CAVs,通过训练线性SVM来寻找概念的方向(即向量)。
- 基于多模态模型 (CLIP-based⭐):这是论文的亮点。如果骨干网是 CLIP,我们可以直接用文本编码器生成概念向量。
值得一提的是,由于CLIP具有一个image encoder和一个text encoder 可以将二者编码到shared embedding space中,因此我们可以通过mapping the prompt using the text encoder to obtain the concept vectors。举例来说,如果我们想得到“strpes/条纹”这一 concept 对应的 CAV 但是又缺少标注好的数据,我们可以通过将“stripes”输入到 CLIP 的 text encoder 中,使用其编码后得到的向量作为CAV(其实就不叫CAV了,但是得到的这个向量也是类似CAV的一种用来表示概念的向量;为方便理解,此处索性就统一叫作CAV)。
CAVs 与 Multimodal Models 两种方法二选一,而不是将两种方法得到的 CAV拼接起来。此外,对于 Classification Task,PCBM指出可以使用 ConceptNet (Speer et al., 2017) 来自动获取与类别相关的 concepts。
特征投影与瓶颈层
给定输入图像,预训练骨干网络输出特征,PCBM 计算其特征向量 在各个概念向量上的余弦相似度(或投影长度):
这一步其实就相当于把原来的高维特征投影到由基向量张成的空间中,即压缩成了概念空间中的 维向量(并且是归一化后的),代表当前输入在第 个方向上的长度(是一个scalar,直观来说就是当前输入中包含概念 的程度)。
然后,PCBM 训练一个稀疏线性层 (Sparse Linear Layer) 来预测目标。为了保证解释性,必须让模型只选择最重要的几个概念,因此引入 L1 正则化(LASSO):
到目前为止,这被称为 PCBM (Standard)。

残差建模 (PCBM-h)
作者承认:无论概念库多大,人类定义的语义概念永远无法包含图像的所有信息(如微小的纹理差异、背景噪声)。 原版 CBM 精度低就是因为丢掉了这些信息。为了挽回精度,作者提出了 Hybrid PCBM (PCBM-h),引入了残差分支。
直观理解:
- 可解释路径说:“因为有‘长喙’和‘蓝翅膀’,所以是翠鸟。”
- 残差路径说:“还有一些其他的像素特征,我不确定叫什么名字,但也指向翠鸟。”
- 两者加和,既保证了核心逻辑是基于概念的,又利用了残差特征补全了精度。
模型干预
与原版 CBM 只能对单个样本做干预(local intervention)不同,PCBM的一个优势就是允许 global intervention,从而直接提升模型整体的表现。
当我们知道某些概念是错误的时候,可以通过剪枝(Prune)等操作优化模型。举个例子,如果训练集和测试集存在域偏差,比如,训练集中有很多“狗”的图片,但是在测试集中没有“狗”的图片,那么在训练阶段学习到的所有关于狗的概念都将无效,或者说对于测试集是“错误的概念”;此时我们可以采用以下三种决策对模型进行修改:
- Prune: 在决策层将错误概念对应的权重置0;
- PruneNormalize:在prune后rescale the concept weights,归一化可以缓解剪枝后较大权重造成的权值不平衡问题;
- Fine-tune (Oracle):在测试集上对整个模型进行微调。
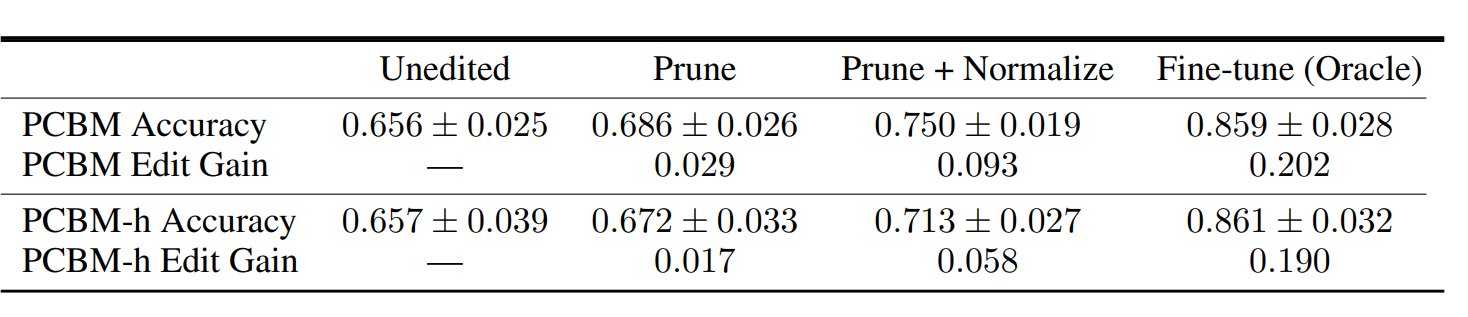
通过实验可以发现PCBM进行PruneNormalize之后的增益较高,最接近oracle;而PCBM-h的增益很低。一个原因是PCBM可以通过Prune直接剪掉干扰预测的错误概念,但是由于PCBM-h的残差连接中仍包含来自错误概念的信息无法被去除,因此预测精度的提升不明显。
Label-free CBM
Title:Label-Free Concept Bottleneck Models (ICLR 2023)
Link:https://arxiv.org/abs/2304.06129
纵观前面我们介绍的各种变体CBM,它们都面临一个极其现实的阻碍:
- 标注昂贵:如果你想训练一个识别鸟类的 CBM,你需要专家为数万张图片标注“喙的长短”、“翅膀颜色”等数百个属性。
- 概念定义难:人类很难穷举出区分所有类别的完美概念集。
LF-CBM 的核心思路: 利用 大语言模型 (LLM) 的“知识库”功能来定义概念,利用 多模态模型 (VLM/CLIP) 的“视觉识别”能力来标注概念,最后通过一个简单的稀疏线性层将这些概念组合成决策。此外,它是第一个扩展到 ImageNet 的 CBM。与 PCBM 类似,它也允许将任何神经网络转化为 Label-free CBM。
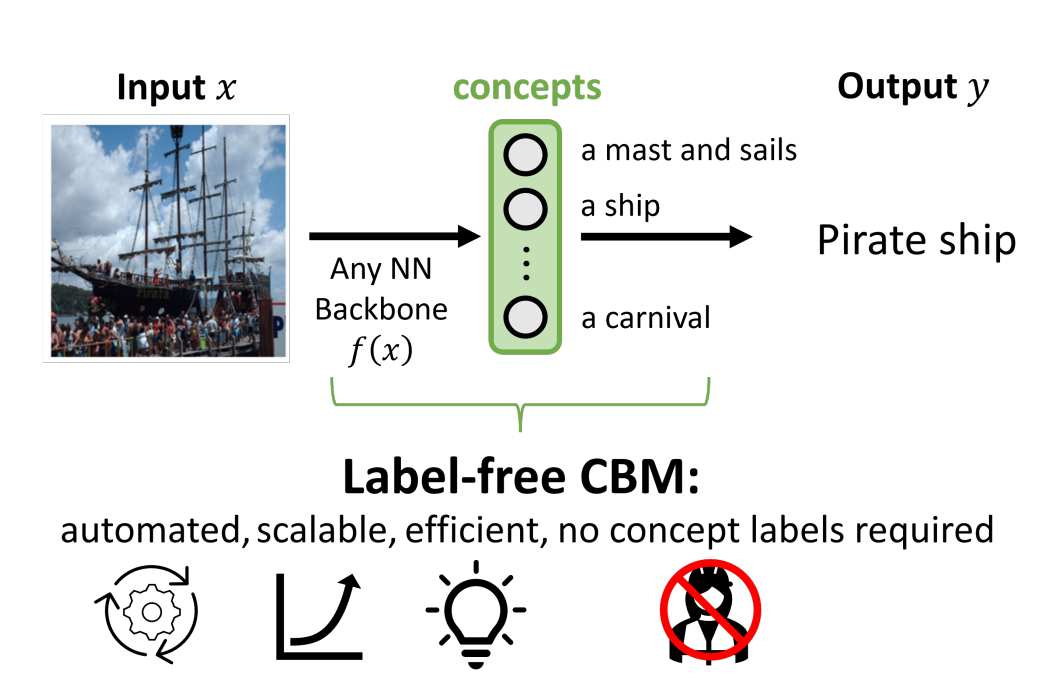
概念生成与筛选
LB-CBM 使用 GPT-3 来生成 concept,具体使用到了以下提示词:
List the most important features for recognizing something as a {class}:List the things most commonly seen around a {class}:Give superclasses for the word {class}:
为了减少结果的方差,询问GPT-3两次并把所有得到的结果整合起来;可以预见的是,整合在一起的这些结果是是很庞大的,并且会存在冗余、噪声,因此需要在B步骤中对其进行 filtering;此外,作者发现使用 GPT-3 产生的结果好于在PCBM 论文中使用的 ConceptNet,具体原因分析见 Appendix A.6。
在筛选阶段,主要通过以下规则对多余的概念进行剔除:
- 删除长度过长的概念: 删除了所有长度超过30个字符的concepts,以保证概念simple并且避免不必要的complication;
- 删除与类别过于相似的concepts:通过使用CLIP ViT-B/16 text encoder以及all-mpnet-base-v2 sentence encoder,将concept与class映射到text embedding space中,进一步比较二者在该空间中的cosine similarity;综合考虑计算得到的两个相似度(一个CLIP text encoder,一个all-mpnet),并删除所有similarity大于0.85的concepts;
- 删除彼此相似的concepts:方法同2,删除与已经存在于概念集中的concept相似度大于0.9的concepts;
- 删除在训练集中不存在的concepts:因为GPT并没有看到training set,因此它给出的concept也许并不存在于当前training set;设置一个dataset-specific cut-off,然后remove any concepts that don’t activate CLIP highly (delete all concepts with average top-5 activation below the cut-off)
- 删除无法正确projection的concepts:Remove neurons that are not interpretable from the CBL. 这一步会在稍后详细说明。
概念投影层
与 PCBM 直接将 CLIP text encoder 得到的向量作为基向量并投影原 representation (或者理解为将 representation 与 概念向量的相似度分数作为概念层的输出)不同,LF-CBM 是学习一个投影矩阵 ,使得原 representation 能够投影到低维瓶颈的概念层,而这个投影层的 Loss 则是通过对其 CLIP 相似度获得的。不过笔者认为这其实是在做类似的操作,只是后者更具有灵活性和可拓展性。
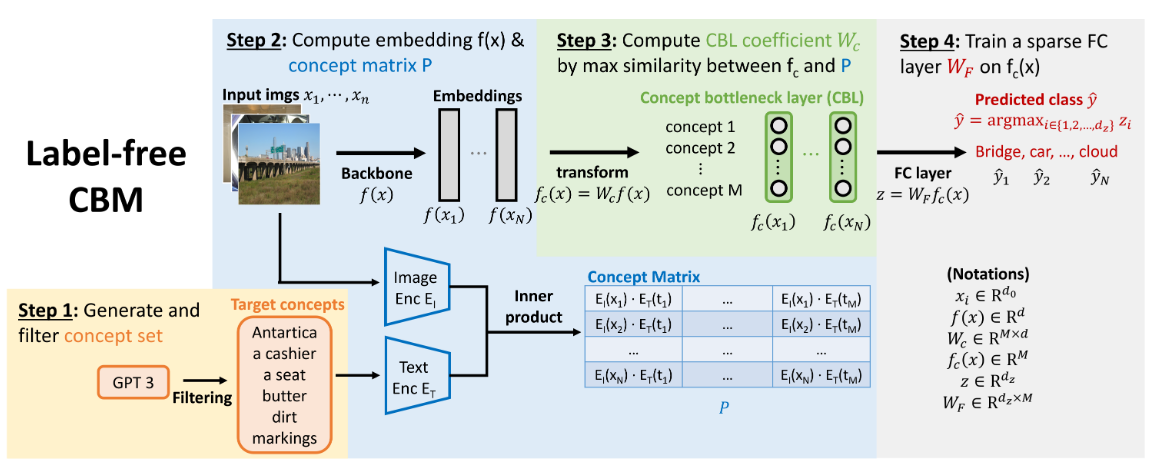
如图所示,作者首先利用所有训练集样本与 concept set 构建一个 Concept Matrix,然后“按列”进行相似度匹配,其中相似度采用 cos cubed similarity(其实就是 cosine similarity 升到3次并归一化);升到3次可以使 similarity 对 highly activating inputs 更敏感。具体来说,投影层的 Loss 如下:
其中, 代表的是归一化(均值0方差1)的 表示所有 个训练集样本对于概念 的分数,亦即经过投影层 之后的第 个神经元结果。而 则表示 Concept Matrix 的第 列的归一化,代表着样本经过 CLIP Image encoder 和 概念 经过 CLIP text encoder 之间的相似度。
训练了投影矩阵之后,LF-CBM 同样通过稀疏线性层进行下游任务的训练:
其中.
参考
- Concept Bottleneck Models (CBM)-CSDN博客
- Concept Embedding Models: Beyond the Accuracy-Explainability Trade-Off (CEM)-CSDN博客
- Post-hoc Concept Bottleneck Models (PCBM)-CSDN博客
- Probabilistic Concept Bottleneck Models (ProbCBM)-CSDN博客
- Label-Free Concept Bottleneck Models (Label-free CBM)-CSDN博客
- Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors-CSDN博客


