Python进阶学习|Flask框架入门
什么是Flask
Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。它可以很好地结合MVC模式进行开发,开发人员分工合作,小型团队在短时间内就可以完成功能丰富的中小型网站或Web服务的实现。
另外,Flask还有很强的定制性,用户可以根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,其强大的插件库可以让用户实现个性化的网站定制,开发出功能强大的网站。
工作过程:
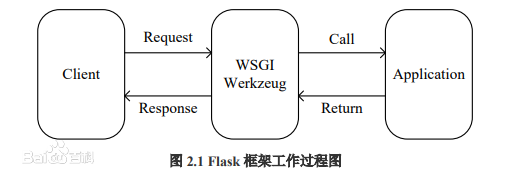
^以上截自:百度百科^
安装与简单配置
建议在开发环境和生产环境下都使用虚拟环境来管理项目的依赖。
虚拟环境
为什么要使用虚拟环境
随着你的 Python 项目越来越多,你会发现不同的项目会需要 不同的版本的 Python 库。同一个 Python 库的不同版本可能不兼容。
虚拟环境可以为每一个项目安装独立的 Python 库,这样就可以隔离不同项目之间的 Python 库,也可以隔离项目与操作系统之间的 Python 库。
虚拟环境的创建
Python 3 内置了用于创建虚拟环境的 venv 模块。
在Windows下,可以使用命令行新建项目目录(也可以自行创建项目文件夹),之后在里面创建venv:
1 | mkdir myproject |
创建完成后项目文件夹中会有一个 venv 文件夹
虚拟环境的激活
在 Windows下,在项目目录下使用命令:
1 | venv\Scripts\activate |
进行激活!之后,即可进行Flask的安装
安装Flask
在已激活的虚拟环境中可以使用如下命令安装 Flask:
1 | pip install Flask |
Flask 现在已经安装完毕。
当然,如果下载不够快,可以自己指定下载源为国内镜像地址~
初步配置使用
在虚拟环境激活了的项目地址下,我们可以新建一个需要使用的python文件(把它保存为 hello.py 或其他类似名称。请不要使用 flask.py 作为应用名称,这会与 Flask 本身发生冲突),之后以如下代码的方式实现使用。
1 | from flask import Flask |
再使用:
1 | if __name__ == '__main__': |
运行内建服务器。
为了便于我们调试,我们通常再通过:
1 | app.debug = True |
开启debug模式,方便调试!
之后再通过命令行窗口进入虚拟环境,再打开即可。
如何使用 Sublime Text 3 打开?
通过ctrl+shift+P,输入pakage control下载安装vitualenv虚拟环境插件。
安装好后,再次通过ctrl+shift+P,输入vir……,打开new(venv)再键入我们安装的环境位置,回车后,通过ctrl+shift+P,输入vir……选择激活即可。
之后可在编辑好的py文件窗口下,直接使用ctrl+B打开
项目中的requirements文件
在项目开发中,特别是语言为python的项目,由于其所依赖的库和包较多,开源分享时,我们不可能将我们开发时所需要的包全部分享出来。因此,为了给使用者一个提示,需要一个 该项目的虚拟环境中安装有哪些包 的文档。
这里,有一个及其方便的方法:
1 | pip freeze > requirements.txt |
命令行中可通过上述命令直接将当前虚拟环境目录下的依赖包名字及版本全部导入到该txt文本文件中。
不仅如此,该方法还可以直接被用于其他用户的一次性安装!
其他用户将该文本文件拷到自己的目录中后,可以直接通过命令:
1 | pip install -r requirements.txt |
一次性将所有所需依赖包全部下载安装至当前目录。(已有的就跳过)
上述中的requirements.txt并不是强制的,可以重命名为任何名字,不过开发中已经约定俗成为此了。
Flask的代码框架
简单模板及解释
在前面的 简单配置中,我们已经初步将一个最简单的web程序在本地小型服务器中跑起来了,但是代码可能还是一头雾水。
下面对上述中的代码,也就是flask的最简单 的 代码进行解析:
1 | # -*- coding:utf-8 -*- |
更加规范化的代码 :点击跳转
路由请求与参数
这里我们继续来讲解一下关于装饰器@app.route().
事实上,该装饰器还支持其他的关键字参数来限制请求,methods
我们可以通过这个关键字参数限定路由的请求方式(包括:GET,POST,PUT等等)
可以通过软件:Postman 进行测试!
该关键字参数需使用列表的方式传入:
1 |
而对于路径,我们还可以添加参数来使得某些路径可以访问
如:
1 |
|
但是这并不完善,通过测试我们知道,我们传入的“id”可以为许多内容,其实实际上就是一个字符串
为了优化和限制,我们了解到“id”是可以有限制的。通过使用 <converter:variablename> ,可以 选择性的加上一个转换器,为变量指定规则.
其中,converter就是变量类型,支持有:
string | 接受任何不包含斜杠的文本 |
|---|---|
int | 只接收正整数 |
float | 只接收正浮点数 |
path | 类似 string ,但可以包含斜杠 |
uuid | 只接收 UUID[^1] 字符串 |
其中str为默认类型。
Jinja2模板引擎
模板的使用
这里需要引入Flask内置的jinja2引擎,这里提供了一个函数:render_template()
通过函数,即可渲染并返回模板。
返回模板:
1 |
|
传入参数以动态使用模板:
在index.html文件中,使用双花括号的方式使得模板可以复用化(下面第八行所示)
1 |
|
然后,在python文件中如下设置:
1 |
|
注意的是使用render_template函数是,里面的关键字参数是html文件中使用的“变量”,值是py文件中设置的变量。上述例子中的url_in_py和url_in_html就是为了便于清楚这一点。
实际上,一般情况下是左右相统一,便于使用。即使用 name = name的方式来传入。
注释:
使用以下方法进行注释
1 | {#{{ name }}#} |
代码块的使用
jinja2模板中的变量代码块可以是任意python中的类型或者对象,比如{{ your_list[0] }}也可以被使用。
当然,还有 控制代码块可供使用,使用方法:花括号+%+内容+%+花括号
举例:
1 | {{ my_list[4] }} |
(在sublime中,装入 jinja2 的插件后,可以通过for+tab快速进行代码补全)
过滤器的使用
变量可以通过“过滤器”进行修改,过滤器可以理解为是jinja2里面的内置函数和字符串处理函数。
使用方法:
1 | {{ 变量 | 过滤器名 }} |
常用的过滤器有:
- safe: 渲染时值不转义
- capitialize: 把值的首字母转换成大写,其他子母转换为小写
- lower: 把值转换成小写形式
- upper: 把值转换成大写形式
- title: 把值中每个单词的首字母都转换成大写
- trim: 把值的首尾空格去掉
- striptags: 渲染之前把值中所有的HTML标签都删掉
- join: 拼接多个值为字符串
- replace: 替换字符串的值
- round: 默认对数字进行四舍五入,也可以用参数进行控制
- int: 把值转换成整型
链式调用
1 | {{ 变量名 | 过滤器1 | 过滤器2 | …… }} |
信息闪现|flash扩展
web应用中,常会使用到闪现的功能。
如:原始的简单web表单制作时,需要对用户输入密码是否错误等等进行闪现提示,因此,Flask中的flash扩展可以实现。
具体使用中,需要对内容进行加密,因此需要设置一个secret_key,进行加密混淆。
在py文件中:
1 | from flask import Flask,render_template,flash |
在html文件中:
1 | {# 使用函数get_flashed_messages()获取内容 #} |
WTForms扩展
基本了解
WTForms是一个Flask集成的框架,或者是说库。用于处理浏览器表单提交的数据。它在Flask-WTF 的基础上扩展并添加了一些随手即得的精巧的帮助函数,这些函数将会使在 Flask 里使用表单更加有趣。
用法
安装
进入虚拟环境,使用:
1 | pip install flask-wtf |
以安装此依赖。
field字段
WTForms支持HTML字段:
| 字段类型 | 说明 |
|---|---|
| StringField | 文本字段, 相当于type类型为text的input标签 |
| TextAreaField | 多行文本字段 |
| PasswordField | 密码文本字段 |
| HiddenField | 隐藏文本字段 |
| DateField | 文本字段, 值为datetime.date格式 |
| DateTimeField | 文本字段, 值为datetime.datetime格式 |
| IntegerField | 文本字段, 值为整数 |
| DecimalField | 文本字段, 值为decimal.Decimal |
| FloatField | 文本字段, 值为浮点数 |
| BooleanField | 复选框, 值为True 和 False |
| RadioField | 一组单选框 |
| SelectField | 下拉列表 |
| SelectMultipleField | 下拉列表, 可选择多个值 |
| FileField | 文件上传字段 |
| SubmitField | 表单提交按钮 |
| FormFiled | 把表单作为字段嵌入另一个表单 |
| FieldList | 子组指定类型的字段 |
Validators验证器
WTForms可以支持很多表单的验证函数:
| 验证函数 | 说明 |
|---|---|
| 验证是电子邮件地址 | |
| EqualTo | 比较两个字段的值; 常用于要求输入两次密钥进行确认的情况 |
| IPAddress | 验证IPv4网络地址 |
| Length | 验证输入字符串的长度 |
| NumberRange | 验证输入的值在数字范围内 |
| Optional | 无输入值时跳过其它验证函数 |
| DataRequired | 确保字段中有数据 |
| Regexp | 使用正则表达式验证输入值 |
| URL | 验证url |
| AnyOf | 确保输入值在可选值列表中 |
| NoneOf | 确保输入值不在可选列表中 |
应用:实现表单验证
原始的表单验证方法
html文件中:
1 | <body> |
py文件中:
1 | from flask import Flask, render_template, request, flash |
WTF的表单验证方法
py文件中:
1 | # 引入模块FlaskForm父类 |
html文件的<body>中:
1 | <!-- 使用form标签框住代码块 --> |
!==注意== !
使用wtf构建的表单对于密码的处理和flash中为了保护隐私一样,需要设置密钥以加密。
因此,类似下面的语句不能少:
1 | app.secret_key = "hvfksdhgskg" |
负责无法正确打开网页,debug模式显示:A secret key is required to use CSRF.
关于CSRF[^2]:
是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。
为此,我们需要使用csrf_token来阻止这种“恶意行为”的产生。
SQLAlchemy扩展
基本了解
- SQLALchemy 实际上是对数据库的抽象,让开发者不用直接和SQL语句打交道,而是通过Python对
象来操作数据库,在舍弃一些性能开销的同时,换来的是开发效率的较大提升。 - SQLAlchemy是一 个关系型数据库框架,它提供了高层的ORM和底层的原生数据库的操作。flask-
sqlalchemy是一个简化了SQL Alchemy操作的flask扩展。
安装
1 | pip install flask-sqlalchemy |
如果连接的是mysql数据库,需要安装mysqldb数据库驱动
1 | pip install flask-mysqldb |
当然,前提是安装有MySQL.
SQLAlchemy支持多种数据库,如:MySQL,SQLite……
以下以链接MySQL数据库为例细说。
(关于MySQL的知识移步> MySQL数据库|基础入门 <)
配置Key
Flask-SQLAlchemy 扩展能够识别的配置key的清单:
| Key | 作用 |
|---|---|
SQLALCHEMY_DATABASE_URI | 用于连接数据的数据库。例如:sqlite:////tmp/test.db``mysql://username:password@server/db |
SQLALCHEMY_BINDS | 一个映射绑定 (bind) 键到 SQLAlchemy 连接 URIs 的字典。 更多的信息请参阅 绑定多个数据库。 |
SQLALCHEMY_ECHO | 如果设置成 True,SQLAlchemy 将会记录所有 发到标准输出(stderr)的语句,这对调试很有帮助。 |
SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或者启用查询记录。查询记录 在调试或者测试模式下自动启用。更多信息请参阅 get_debug_queries()。 |
SQLALCHEMY_NATIVE_UNICODE | 可以用于显式地禁用支持原生的 unicode。这是 某些数据库适配器必须的(像在 Ubuntu 某些版本上的 PostgreSQL),当使用不合适的指定无编码的数据库 默认值时。 |
SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是数据库引擎的默认值 (通常是 5)。 |
SQLALCHEMY_POOL_TIMEOUT | 指定数据库连接池的超时时间。默认是 10。 |
SQLALCHEMY_POOL_RECYCLE | 自动回收连接的秒数。这对 MySQL 是必须的,默认 情况下 MySQL 会自动移除闲置 8 小时或者以上的连接。 需要注意地是如果使用 MySQL 的话, Flask-SQLAlchemy 会自动地设置这个值为 2 小时。 |
SQLALCHEMY_MAX_OVERFLOW | 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。 |
SQLALCHEMY_TRACK_MODIFICATIONS | 如果设置成 True (默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。 |
^以上截自中文文档^
具体配置框架:
一般情况下,我们需要在python文件中,进行如下配置:
1 | from flask import Flask, render_template |
关于URI,肯定需要自己先在SQL shell或命令行窗口新建好一个数据库,然后再按照规则填写配置好。
不同数据库的的URI配置方法参见 flask-sqlalchemy中文文档
模型
| 数据类型 | 说明 |
|---|---|
| Integer | 整型 |
| String | 字符串 |
| Text | 文本 |
| DateTime | 日期 |
| Float | 浮点型 |
| Boolean | 布尔值 |
| PickleType | 存储一个序列化( Pickle )后的Python对象 |
| LargeBinary | 巨长度二进制数据 |
为了更好理解和使用,下面来创建一个表的模型:
1 | # 建立数据库模型 |
当然,以上的模型建立还不是很完善,我们后面了解到 [模型关联|点击跳转] 时,会再次完善。
基本操作
创建表
即通过运行主文件,使得通过代码方式在指定数据库创建相应的表
此处会遇见许多坑,要么是python2与python3的冲突,要么是 “上下文联系”问题。
报错:
No application found. Either work inside a view function or push an application context事实上,flask-sqlalchemy官方文档最新版已经明确格式了,下面仅作记录。
报错的解决方法:
1 | # 在许多地方,能看见别人的源码是直接通过: |
综上所述,我们以后创建表的时候可以这样做:
1 | if __name__ == '__main__': |
关于更多上下文有关的内容详见 :Flask的Context(上下文)学习笔记
增删改
下面我们进入命令行窗口进行操作:
在虚拟环境内通过python命令进入python的窗口(python2是使用ipython命令)
^(以下以上面我们创建的表为例进行操作)^
导入py文件:
1 | from yourpyfile import * #引入我们的py文件内所有的东西,当然也可以选择性引入 |
添加
1 | role = Role(id = 1,name = "admin") #创建一个Role的实例 |
修改
1 | role.name = "user" |
删除
1 | db.session.delete(role) |
回滚
1 | db.session.rollback() |
查找
待更新
模型关联
为了解决“多个模型之间互相指引,并显示部分内容”的问题,构建模型关联
对于之前创建的表:
User中,每个成员都有一个role_id(身份ID),而每个id具体代表什么意思 又需要去查看另一张表,较不方便。但是如果在User类里创建一个新的属性来保存,又不符合我们的需求和规范,而且还不易于管理。
因此,为了解决这类问题,模型的关联是必要的。
添加关联
在主表/主键的Class定义中,添加如下代码:
1 | var_in_CN1 = db.relationship('ClassName2',backref = 'var_in_CN2') |
其中,var_in_CN1,代表variable_in_ClassName1,即表1中的定义的一个 变量/属性
同理,var_in_CN2为 表2中的定义的 变量/属性
这里使用了db.relationship()方法,区别于db.Column(),后者是添加一个实属性可在数据库中查看到,而前者是添加关联以引用表2的内容,属性内容可通过相关命令或代码语句查出。
- 传入的
第一个参数是所选择关联的副表/外键 backref设置反引用,值为在副表中可用于反引用主表的属性名,于是就不用再在表2的class定义时再添加属性- lazy决定了 SQLAlchemy 什么时候从数据库中加载数据:
'select'(默认值) 就是说 SQLAlchemy 会使用一个标准的 select 语句必要时一次加载数据。'joined'告诉 SQLAlchemy 使用 JOIN 语句作为父级在同一查询中来加载关系。'subquery'类似'joined',但是 SQLAlchemy 会使用子查询。'dynamic'在有多条数据的时候是特别有用的。不是直接加载这些数据,SQLAlchemy 会返回一个查询对象,在加载数据前您可以过滤(提取)它们。
待更新
项目模块化 I
随着flask程序的复杂程度的加大,将我们所需的内容代码全部添加到一个python文件里是不便于处理和管理的。
因此,我们需要将项目进行 模块化处理。
怎么做?
很容易想到,我们创建一个主py文件:manager,创建app实例,然后在其他副py文件:views 里去引入app,再进行相关操作。设置好之后,再回到主py文件进行引入操作。
但实际上这样会出现一个严重的问题: 循环导包
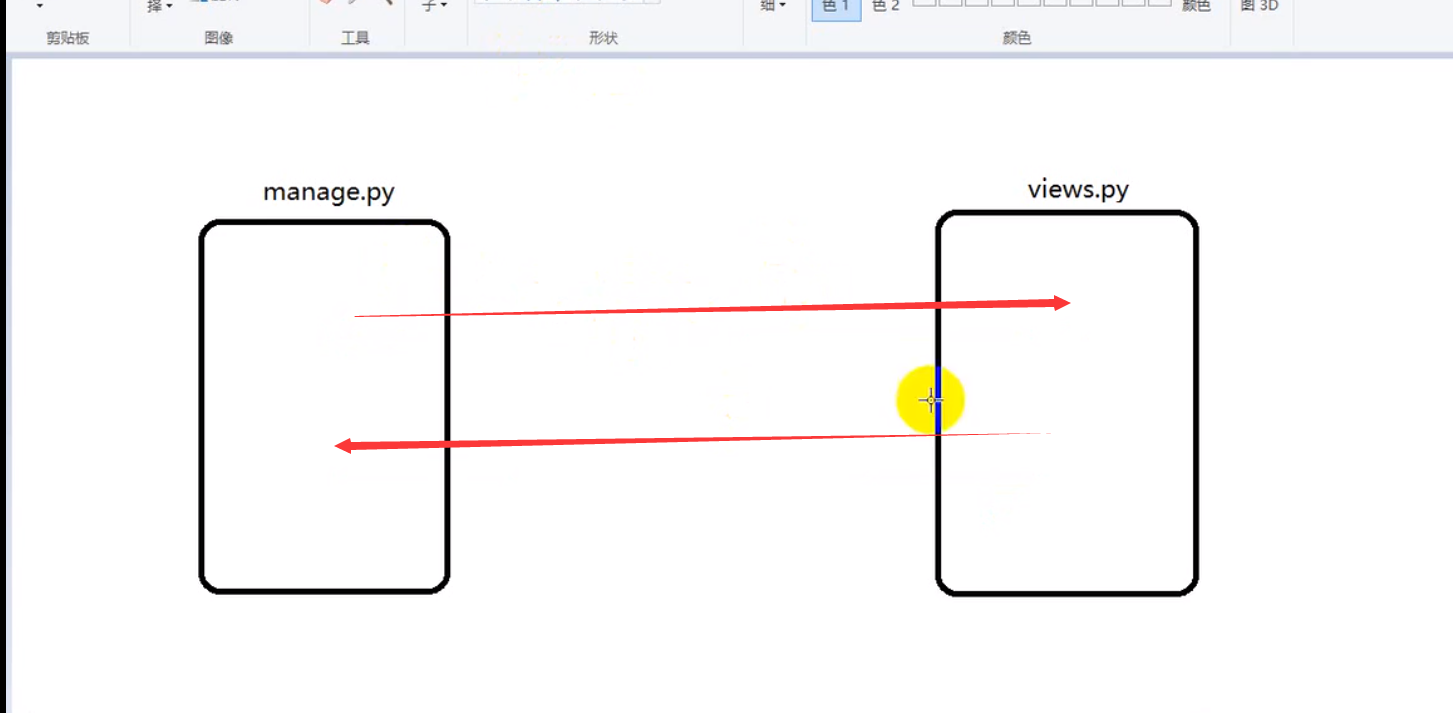
系统是无法处理此类循环问题的。因此,这里我们需要flask的另一个扩展:蓝图
安装Blueprint
虚拟环境下:
1 | pip install flask-blueprint |
使用蓝图
下面是一个最简单的蓝图使用示例:
手动新建一个文件夹,如config,将其作为一个包。(目录下新建文件__init__.py)
在config下,新建views.py作为视图函数的模块来使用。
1 | # views.py 中 |
1 | # __init.py 中 |
1 | # 主运行文件中(manage.py) |
参考资料
[^1]:UUID 的目的是让分布式系统中的所有元素,都能有唯一的辨识资讯,而不需要透过中央控制端来做辨识资讯的指定。如此一来,每个人都可以建立不与其它人冲突的 UUID。在这样的情况下,就不需考虑数据库建立时的名称重复问题
[^2]:跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。跟跨网站脚本(XSS)相比,XSS利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。