
MRel-HGAN - 基于时空App使用行为的用户画像
📑 原始论文:You Are How You Use Apps: User Profiling Based on Spatiotemporal App Usage Behavior
摘要
你是如何使用App的:基于时空APP使用行为的用户画像
移动APP已经成为人们日常生活中不可或缺的一部分。用户根据自己的口味、兴趣和个人需求,根据自己的性格特征,决定使用什么APP以及何时何地使用它们。
本文旨在从用户的时空移动APP使用行为中推断用户画像。
具体来说,我们首先将移动APP使用记录转化为异质图。图上的结点用于表示用户、应用、位置和时隙,边则表示实体在使用记录中的出现的交合连接情况。然后,我们开发了一个多关系异构图注意力网络 ( MRel-HGAN ),这是一个端到端的用户画像系统。
MRel-HGAN首先采用基于自举的邻居采样策略为每个节点采样固定大小的重连接邻居。接下来,我们设计了关系图卷积操作和多关系注意力操作。通过这些模块,MRel-HGAN可以充分利用图中多关系结构的丰富语义信息来进行节点嵌入。
在真实的移动APP使用数据集上进行实验,结果表明了MRel-HGAN在性别和年龄属性的用户画像任务中的有效性和优越性。
问题发现
已有研究的缺陷
- 依赖于手工特征,基于小范围数据,没法应对大范围和带噪声的数据集,泛化能力差
- 没有利用时空信息,限制了建立用户画像模型的表现力
相反,在推断用户画像方面,本研究使用移动app的数据具有天然的优势:
- 可以收集到大量全面的用户使用行为数据;
- 用户选择的app和app自带的属性就反应了ta的人物特征;
- app包含的时空信息也有助于推断用户特征.
利用数据的困难
- app记录存在4种异质的特征,如何在graph中识别并选择有用信息?
- 由于数据本身的特性,图中一个用户会连接大量地点和app,这会对基于图的表示学习方法造成严重的邻域膨胀和过平滑问题。
- 时空app携带有不同类型的不直接的关系(边edge),不同联系有着不同的语义,如何将其表示在结点上也是个挑战。
邻域膨胀
利用GNNs处理稠密图时,不断往下递归
过平滑
节点之间的密集连接使得学习到的表示不可区分,这损害了用户画像的准确性。
邻接节点的度不平衡
度数高的节点的表示可能会被弱连接的邻居破坏,度数低的节点的表示可能无法充分学习。
例如,拥有百万级别用户的 FaceBook 的用户使用量远比小众app多。
方法介绍
形式化
给定用户的app使用行为记录 和用户的画像标签.
其中, 包含多条记录,每条记录 都包括用户、应用程序、用户位置信息 和该记录的时间戳.
该问题的目标是找到一种映射 ,实现将 作为输入的情况下给出用户的画像,可归类为多标签分类问题。
异质图的构建
采用多关系异质图 来对app使用行为记录进行编码。每个结点代表着记录中四种类型的数据,每条边代表记录中的相互联系。
特别地, 表示顶点(Vertex)集的类型, 表示关系类型, 是每个顶点的特征向量集合。
包括 和 4种类型;
包括 (指 这条边/关系,其他类似)、、 等等.
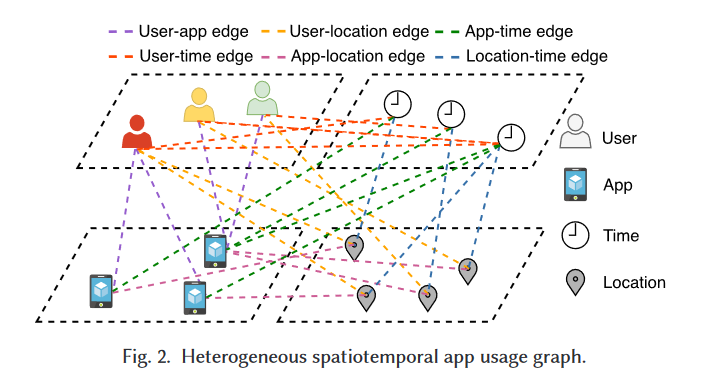
虽然时间是连续变量,但为了简单起见,本研究中将其划分为若干个小的时间段进行分析。
为对该异质图中各顶点的连接强度进行建模,提出按照如下策略进行加权:
- 初始时,每个顶点之间的边权均置零;
- 遍历每条记录, 依次对这些顶点两两相连,即一下边的权重加1:
- 总体对边权进行最小最大归一化,以解决App使用记录分布不均的问题。
顶点特征提取
为了利用丰富的顶点信息,为每个顶点 都定义一个特征向量.
- 顶点:利用应用商店所给的类别标签作为特征,使用 one-bot 编码 构成特征向量;
- 位置顶点:利用任意位置 附近的 POIs 中各 POI 类别 的数量组成的向量 作为指标。为解决POI类别不平衡问题,利用 TF-IDF 技术进行标准化;
- 时间顶点:准确来说是时间段顶点,同样用独热编码构成特征向量;
- 用户顶点:独热编码构成特征向量。
邻点采样
对于每种类型的顶点 ,我们以与边权重成比例的概率随机采样一个固定大小的 的邻点集合,然后将其近似看作该顶点的邻点聚合,参与后续计算。
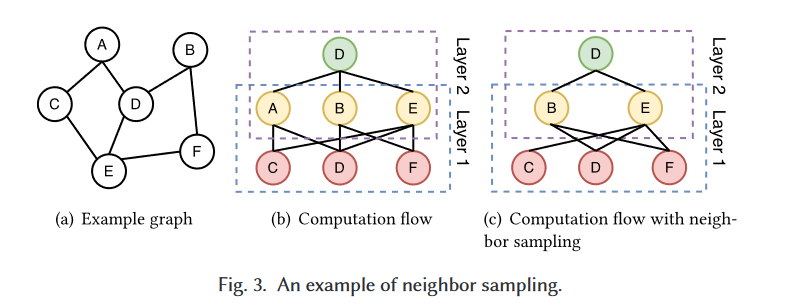
Fig. 3. © 就是设定固定大小为2时,与 (b) 相比删去了 的其中一条边 之后得到的简化图 。
这项举措解决了前面提到的邻点扩张、过平滑以及度不平衡(因为大小固定了)三种已有的问题。
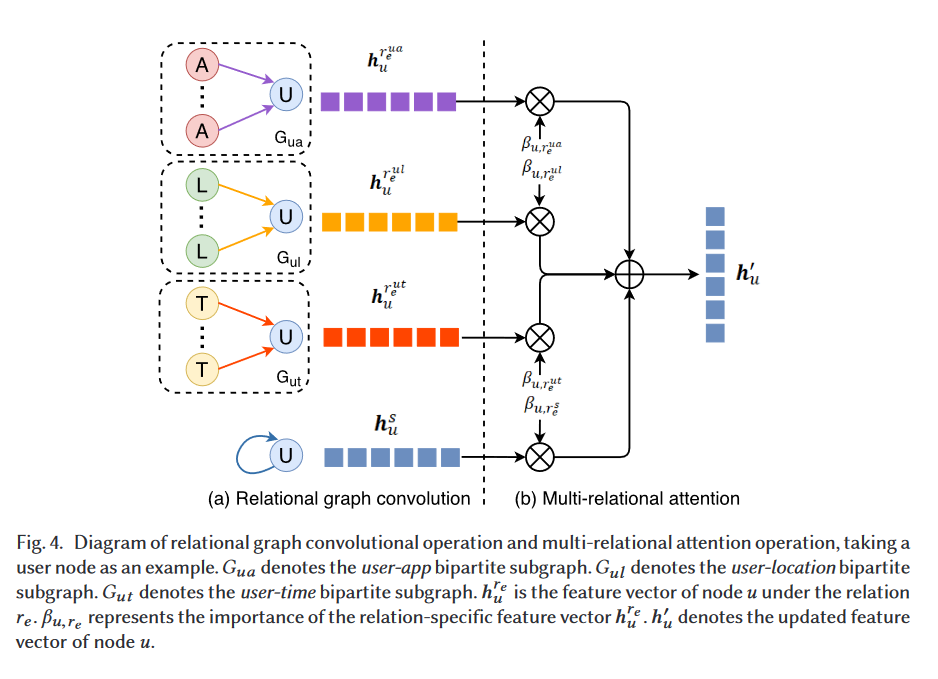
关系图卷积
由于顶点的异质性,不同类型的顶点的顶点特征向量空间也有所不同。为了便于后续可以进行通用的处理,我们将对其特征向量进行变换,从而得到投影特征向量:
其中, 表示顶点 的类型 所使用的变换矩阵, 为结点 的特征向量。
此外,应用使用的异质图的边的类型也各不相同,传统的图卷积方法不仅对边相等的要求颇为严格,也不能提取有用的语义信息。所以我们提出了一种关系图的卷积操作。
对每种类型的边,都增加一个层,对本研究来说就是6个层。这些层只作用于有着相同对应关系的边,也就相当于信息在各自的二部图(将整个异质图 按边类型划分子图的话,每个子图正好都是一个二部图)中传播和聚合。
对于 这种类型的边关系来说,给定一个顶点 ,那么通过我们的关系图卷积操作,可以得到一个关系特征向量,其计算公式如下:
插入公式
多关系注意力
为了统合所有的特定关系特征向量来更新结点的新特征向量(使得每个结点的特征具有同质性,便于后续直接利用 GNN 的方法进行处理),此前得到的顶点特征向量(对应的投影特征向量)需要进行自循环:
插入公式
我们利用 tanh 函数作为激活函数的单层MLP来更新特征向量,通过将原特征向量和注意力向量 相乘来计算不同特征向量的“重要性”,然后利用 softmax函数 对“重要性”进行归一化,得到,从而将其作为权重系数来计算新的特征向量.
插入公式
这个更新得到的新的特征向量就聚合了多关系中所有的语义信息。
建立用户画像
用交叉熵作为损失函数
插入公式


